Command Palette
Search for a command to run...
AnchorWorld: محاكاة العالم المتجسد الذاتي باستخدام تخصيص التطور القائم على المنظور
AnchorWorld: محاكاة العالم المتجسد الذاتي باستخدام تخصيص التطور القائم على المنظور
الملخص
على الرغم من أهمية نمذجة العالم التفاعلية كمجال محوري، إلا أنها لا تزال غير مستكشفة بشكل كافٍ فيما يتعلق بقابلية التحكم المتنوعة التي تتطلبها السيناريوهات العملية. لسد هذه الفجوة، نقدم إطار عمل AnchorWorld الذي يطور محاكاة المنظور الذاتي من خلال تعزيز تكامل التفاعل وآلية مرنة لتخصيص العالم. أولاً، نعتمد على حركة الإنسان ثلاثية الأبعاد كوسيط تفاعل أساسي. ولتكميل أجزاء الجسم التي تقع خارج نطاق الرؤية أو تكون مقطوعة في المشاهد ذاتية المركز، نقدم إشرافاً تدريبياً مساعداً يدمج زوايا نظر خارجية مفصولة عن الإدراك الحسي من منظور الشخص الأول للـ agent. ويتيح ذلك للنموذج مراقبة وضع جسم الـ agent بالكامل بالنسبة للبيئة، مما يسهل تأسيساً مكانياً أكثر متانة لتفاعلات الإنسان مع العالم. علاوة على ذلك، نقترح آلية بسيطة وفعالة لتخصيص العوالم ذاتية التطور. ويتحقق ذلك من خلال تعريف مشاهد مرجعية ضمن نظام إحداثيات عالمي موحد، مقترنة بوصف نصي يوجه التطور الديناميكي للمشهدات المحلية. وتُظهر النتائج التجريبية أن AnchorWorld يتفوق بشكل ملحوظ على النماذج الأساسية الأكثر تطوراً، في حين تؤكد دراسات التحليل التنازلي فعالية تصاميمنا الرئيسية. وتجدر الإشارة إلى أن مخطط التخصيص المقترح يُظهر اتساقاً هندسياً زمكانياً واعداً، ويلتزم بدقة بالديناميكيات التطورية المحددة مسبقاً.
One-sentence Summary
AnchorWorld is an egocentric world simulation framework that enhances spatial grounding through 3D human motion interaction and auxiliary exogenous viewpoint supervision to compensate for truncated body parts, while its view-based evolution customization mechanism integrates anchor coordinates with textual descriptions to generate scenes with spatio-temporal geometric consistency that outperform state-of-the-art baselines and strictly adhere to prescribed evolutionary dynamics.
Key Contributions
- This work formulates world-customizable embodied egocentric simulation and introduces AnchorWorld, a unified framework for human-motion-driven exploration within self-evolving environments.
- The approach utilizes 3D human motion as the primary interaction modality and applies auxiliary training supervision with exogenous viewpoints to address truncated body parts in first-person views.
- Pose-associated anchor views paired with textual evolution prompts guide localized scene customization, while extensive evaluations across egocentric, synthetic Unreal Engine, and real-world scenarios validate accurate action control, robust spatial consistency, and controllable dynamic evolution.
Introduction
Interactive world models are critical for first-person applications like virtual reality and embodied AI, as they must translate human motion into coherent visual experiences while preserving customizable environmental states. Prior approaches typically rely on abstract controls such as text prompts or camera trajectories, which fail to capture true embodied interaction. Even recent methods that incorporate full-body motion struggle with egocentric video generation because the first-person perspective obscures the body, resulting in sparse and weakly aligned motion supervision. Additionally, existing models define scenes implicitly through initial frames or global prompts, making it difficult to specify, preserve, or evolve local visual states at precise 3D locations. To bridge these gaps, the authors introduce AnchorWorld, a unified framework that combines hybrid-view human action conditioning with pose-associated anchor views. This architecture enables the model to learn motion dynamics from external perspectives while allowing users to explicitly define and guide the appearance and evolution of localized scene elements. Through a progressive training strategy, the framework delivers accurate egocentric action control, robust spatial consistency, and controllable dynamic world evolution across synthetic and real-world scenarios.
Method
The authors leverage a flow-matching-based DiT video generation model, instantiated as Wan [46], to synthesize egocentric videos conditioned on embodied human motion and anchor views. The framework operates by receiving two primary control signals: a sequence of human actions derived from the SMPL-X parametric body model, represented as M∈Rf×k×6, where f is the number of frames and k is the number of joints, and a customizable world specification defined by an initial egocentric view and a set of localized anchor views. Each anchor view consists of an RGB image, a 6-DoF viewpoint pose, and an evolution prompt describing the temporal change of the local scene. The overall architecture integrates these inputs through a series of conditioning mechanisms to generate coherent and controllable egocentric video outputs. 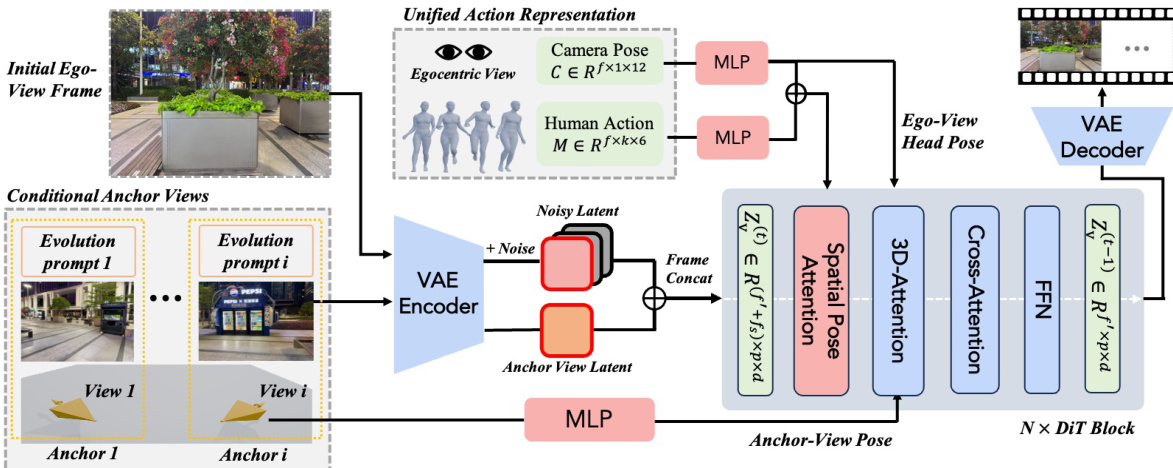
To achieve robust action control in the egocentric domain, the authors introduce a hybrid-view training approach that combines third-person view (TPV) and first-person view (FPV) data. This method addresses the limitation of sparse and incomplete supervision in first-person views by utilizing TPV videos, which provide full-body motion and interaction cues. The action conditioning is formulated in a projection-based manner, enabling the model to project 3D human motion into 2D visual observations under arbitrary viewpoints. The model is first pre-trained on large-scale TPV videos to acquire projection knowledge and human-scene interaction priors, then adapted to egocentric simulation by aligning camera parameters with the human head perspective in FPV data. This design enhances the model's ability to perform accurate human-action control and develop stronger spatial pose awareness. 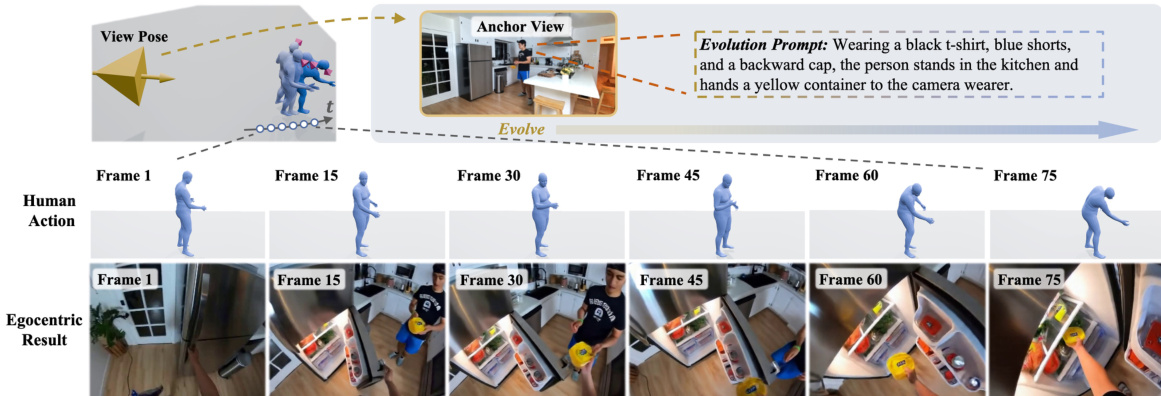
The action conditioning is implemented using a spatial pose attention mechanism. A motion encoder projects the input motion sequence M into a latent embedding zm∈Rf′×k×d, where d is the model's hidden dimension, and a camera encoder processes the camera pose sequence C∈Rf×3×4 into zc∈Rf′×1×d. These embeddings are concatenated with the video tokens zv(t) along the spatial dimension to form a unified sequence T=[zv(t);zm;zc]∈Rf′×(h⋅w+k+1)×d. This sequence is then processed by a spatial self-attention block, where the Truncate operator discards the auxiliary pose tokens, retaining only the updated video features. This mechanism allows the model to exploit the frame-wise correspondence between motion and video tokens, enabling effective integration of action and viewpoint information. 
For evolvable world customization, the framework employs a set of anchor views, each providing three types of localized world priors: an RGB image for visual appearance, a 3D pose for spatial grounding, and an evolution prompt for temporal state evolution. To incorporate anchor-view image priors while preserving the generative capability of the pre-trained video model, an in-context conditioning strategy is adopted. The images of anchor views are encoded into latent tokens zs∈Rfs×h⋅w×d, which are concatenated with the video latent tokens zv(t)∈Rf′×h⋅w×d along the frame dimension. This design enables anchor views to guide world synthesis in-context without requiring architectural modifications. The model further employs 3D RoPE to differentiate anchor views by assigning them distinct frame-axis positions in the positional embedding space. 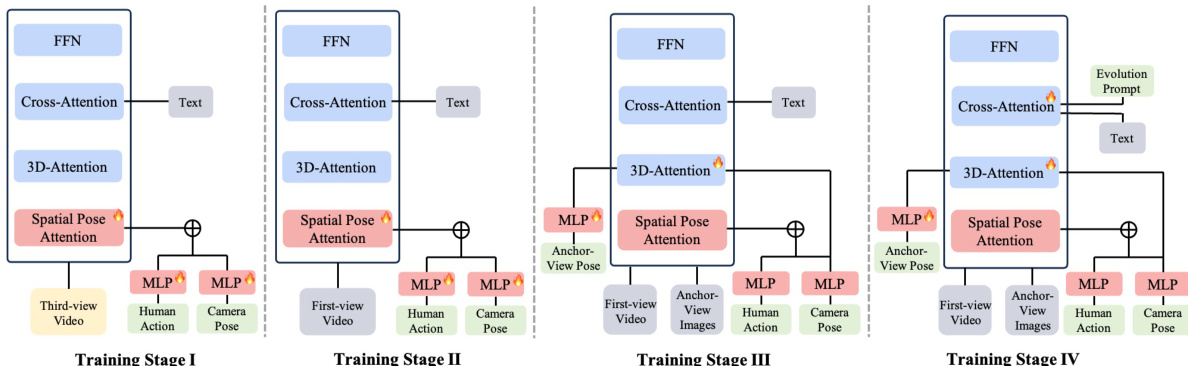
To ground the customized content spatially, the camera poses are encoded into embeddings zpose∈R(f′+fs)×1×d and spatially broadcast to match the latent resolution, yielding zpose∈R(f′+fs)×h⋅w×d. Before the self-attention layers, these pose embeddings are added to the visual tokens, enabling the model to distinguish anchor views located at different positions and associate the generated egocentric trajectory with the correct local constraints. For dynamic world customization, each anchor view is paired with a localized evolution description ti that specifies its temporal scene changes. These descriptions are injected through cross-attention, leveraging the semantic priors of the pre-trained video model. To preserve the locality of dynamic instructions, an attention mask restricts the interaction between text prompts and visual tokens, ensuring that a text prompt tj interacts only with the generated video tokens and the corresponding anchor-view tokens zs(j). This masked cross-attention enables anchor-specific text control, allowing local scene states to evolve over time while reducing interference across different anchor views.
The model is trained using a progressive multi-stage strategy to gradually equip it with egocentric human action control and evolvable anchor-view customization. Stage I and II focus on hybrid-view action control training, where Stage I trains the model on large-scale third-person videos to learn action-conditioned generation from external viewpoints, and Stage II adapts the model to first-person videos by aligning the camera trajectory with the head pose of the character. Stage III and IV focus on evolvable anchor-view customization training. Stage III trains the model on static scenes to learn pose-aware anchor-view conditioning for consistent egocentric roaming, and Stage IV mixes in dynamic data with evolution descriptions to model text-driven local state changes. This staged approach ensures the model learns to integrate action and world priors effectively, enabling the synthesis of coherent and controllable egocentric videos.
Experiment
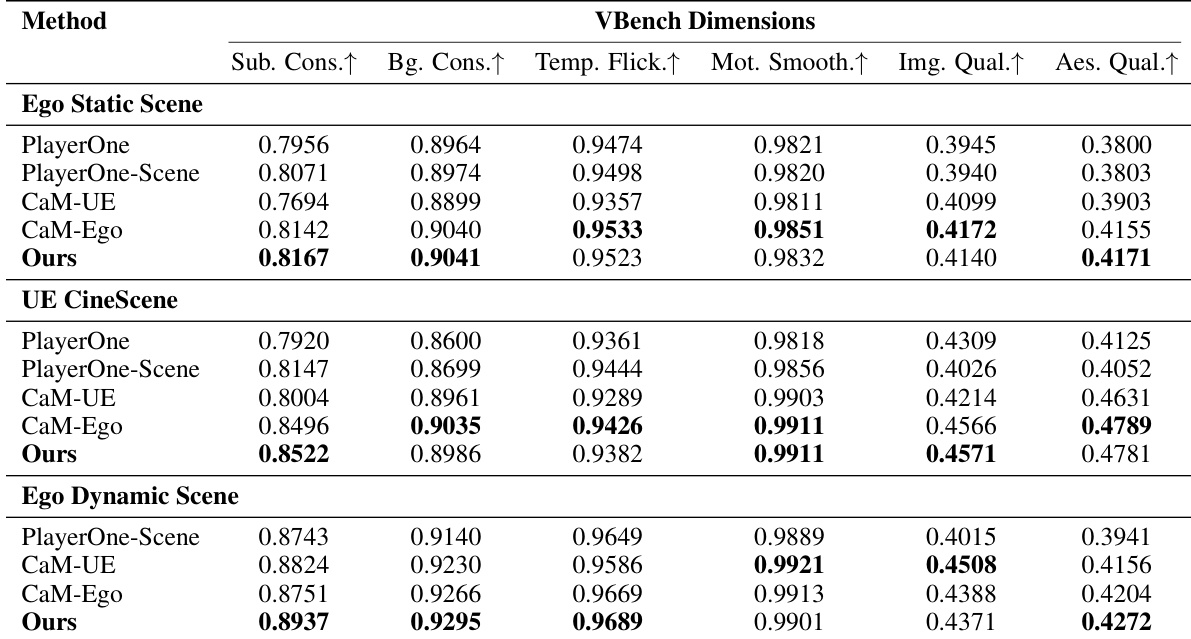
The evaluation spans static and dynamic egocentric scenarios across multiple test sets, validating the model’s capabilities in human action control, spatial scene consistency, and prompt-driven dynamic evolution. Comparative analyses demonstrate that the proposed approach significantly outperforms existing baselines in motion accuracy and spatial perception, while maintaining robust generalization on out-of-distribution and real-world footage. Ablation studies further confirm that the multi-stage training pipeline, projection-based control mechanism, and anchor-view conditioning are essential for accurate pose awareness and successfully inferring unseen scene dynamics.
{"summary": "The authors evaluate their method against several baselines across different test scenarios, including static and dynamic scenes, and demonstrate superior performance in scene consistency, camera accuracy, and text alignment while maintaining competitive visual quality. The results highlight the effectiveness of their projection-based control and multi-stage training approach, particularly in handling complex egocentric interactions and dynamic scene evolution.", "highlights": ["The proposed method achieves the best performance in scene consistency, camera accuracy, and text alignment across all test scenarios compared to baselines.", "The method shows strong generalization in dynamic scenes, with improved results in motion control and visual quality when handling evolving actions.", "Ablation studies confirm the importance of key design choices, including projection-based control and multi-stage training, for robust scene understanding and pose-aware generation."]
The authors present a multi-stage training framework for video generation, with each stage focusing on progressively more complex tasks such as exocentric motion, egocentric motion, static scene consistency, and dynamic scene evolution. The training process uses different data scales and settings across stages, with consistent optimization and hardware resources throughout. The framework progresses through four stages, each with distinct objectives and data requirements, starting from exocentric motion and ending with dynamic scene evolution. Training data scale decreases from the first to the third stage, while the fourth stage uses a combination of data from previous stages. The same optimizer, hardware resources, and learning rate are maintained across all stages, with only the number of iterations varying.
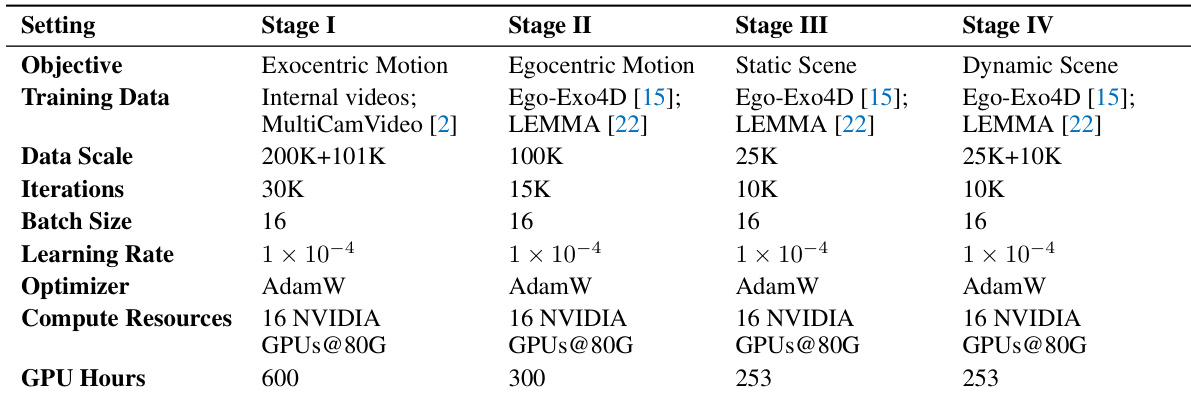
The authors conduct an ablation study to evaluate the impact of different design strategies on motion accuracy, focusing on joint position, 3D pose attention, and cross-attention fusion. Results show that their method achieves the lowest error in both WA-MPJPE and PA-MPJPE metrics, indicating superior motion accuracy compared to alternative approaches. The proposed method outperforms alternatives in motion accuracy metrics, achieving the lowest error values. Joint position-only and 3D pose attention approaches show higher error values, indicating less accurate motion control. Cross-attention fusion and in-context frame concatenation also exhibit higher errors, suggesting limitations in motion accuracy compared to the proposed method.
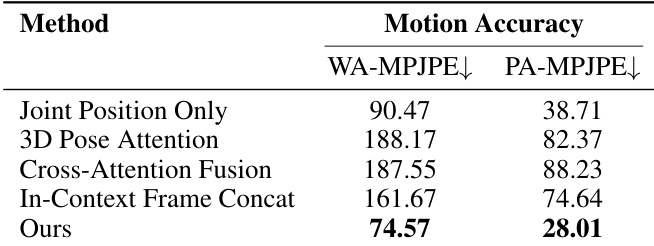
The authors evaluate the impact of the number of anchor views on scene consistency metrics, observing that increasing the number of anchor views generally improves performance across most metrics. Results show that using three anchor views leads to the best performance in most cases, particularly in matching pixel-level details and semantic consistency, while also achieving the highest scores in certain quality measures. Performance improves with more anchor views, with three views yielding the best results in most metrics. Using three anchor views achieves the highest scores for matching pixel-level details and semantic consistency. The method shows strong performance in visual quality and consistency, particularly with an increased number of anchor views.
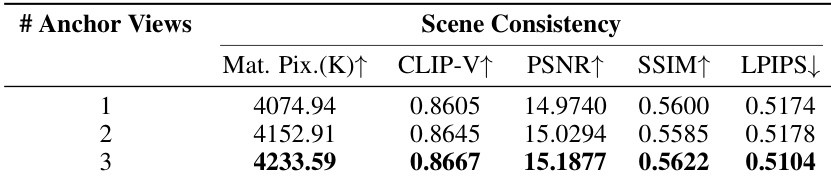
{"summary": "The authors conduct ablation studies to evaluate the impact of different design choices on their method's performance across action control, scene consistency, and text alignment. Results show that removing key components such as Stage I training, projection-based control, anchor-view pose, or anchor-view RoPE leads to significant degradation in performance, particularly in scene consistency and camera accuracy. The full method achieves the best results across all metrics, demonstrating the effectiveness of the multi-stage training and spatial awareness mechanisms.", "highlights": ["Removing Stage I training or projection-based control significantly reduces scene consistency and camera accuracy.", "Omitting anchor-view pose or anchor-view RoPE leads to worse performance in scene consistency and camera accuracy.", "The full method outperforms all ablated variants in both static and dynamic scene evaluations, showing superior text alignment and visual quality."]
The authors evaluate their multi-stage video generation framework across static and dynamic scenarios, validating its capacity to maintain scene consistency, camera accuracy, and text alignment while managing complex egocentric interactions. Ablation studies confirm that critical design elements, including projection-based control, anchor-view positioning, and progressive training stages, are essential for robust spatial understanding and precise motion tracking. Qualitative assessments further demonstrate that the method consistently outperforms baseline approaches in visual fidelity and dynamic scene evolution, with optimal consistency achieved using a moderate number of anchor views. Collectively, these experiments establish that the proposed architecture effectively balances fine-grained motion control with coherent scene generation across diverse video conditions.