Command Palette
Search for a command to run...
SWE-Explore: تقييم كيفية استكشاف وكلاء البرمجة Agents للمستودعات
SWE-Explore: تقييم كيفية استكشاف وكلاء البرمجة Agents للمستودعات
الملخص
أدت معايير تقييم البرمجة على مستوى المستودعات، مثل SWE-bench، إلى طفرة سريعة في قدرات agents. ومع ذلك، تُعامَل مهام البرمجة عادةً كمشكلة تنبؤ شاملة ثنائية (مثل: مُحلّة أو غير مُحلّة)، مما يتجاهل قدرات agent الدقيقة مثل فهم المستودع، واسترجاع السياق، وتحديد مواقع الكود، وتشخيص الأخطاء. في هذه الورقة، نقدم SWE-Explore، وهو معيار تقييم يعزل عملية تقييم استكشاف المستودعات، وهي قدرة حاسمة لـ agents. وفي ظل وجود مستودع وقضية محددة، يطلب SWE-Explore من المستكشف إرجاع قائمة مرتبة لمناطق الكود ذات الصلة ضمن ميزانية أسطر ثابتة. يغطي SWE-Explore 848 قضية برمجية عبر 10 لغات برمجة و203 مستودعًا مفتوح المصدر. بالنسبة لكل حالة، نستنتج الحقيقة المرجعية على مستوى الأسطر من مسارات agent المستقلة التي نجحت في حل نفس القضية، مستخلصين بذلك مناطق الكود المحددة التي اعتمدتها مسارات الحل فعليًا. نقوّم عملية الاستكشاف عبر أبعاد التغطية، والترتيب، وكفاءة السياق، مُظهرين أن هذه المقاييس تتوافق بقوة مع سلوك الإصلاح التبعي. عبر مجموعة واسعة من طرق الاسترجاع، وagents البرمجية العامة، وأدوات تحديد المواقع المتخصصة، نجد أن المستكشفين الوكيليين يشكلون فئة متفوقة بوضوح على طرق الاسترجاع الكلاسيكية. وعلى الرغم من أن تحديد المواقع على مستوى الملفات أصبح قويًا بالفعل في الطرق الحديثة، تظل التغطية على مستوى الأسطر والترتيب الفعال المحورين الرئيسيين اللذين يميّزان المستكشفين الأكثر تقدمًا.
One-sentence Summary
The authors introduce SWE-Explore, a benchmark that isolates repository exploration by evaluating how coding agents retrieve and rank relevant code regions under a fixed line budget, deriving line-level ground truth from successful agent trajectories to measure coverage and context efficiency, which strongly predict downstream repair success and demonstrate that agentic explorers outperform classical retrieval methods.
Key Contributions
- This paper introduces SWE-Explore, a benchmark that isolates repository exploration as a distinct evaluation target by measuring how coding agents surface relevant code regions prior to patch generation.
- The evaluation framework distills line-level ground truth from successful agent solution trajectories and scores ranked region lists under a fixed line budget to decouple exploration metrics from downstream repair performance.
- The benchmark covers 848 issues across 203 open-source repositories and 10 programming languages, demonstrating through controlled downstream validation that exploration metrics strongly predict patch success and that agentic explorers consistently surpass classical retrieval baselines.
Introduction
Repository-level coding benchmarks have transformed repository-scale issue resolution into a practical testbed for automated agents, yet standard evaluation protocols reduce performance to a binary pass or fail score. This holistic metric obscures the mechanics of agent success by conflating localization failures with patch synthesis errors, leaving line-level exploration capabilities under-measured and preventing rigorous comparison across different retrieval strategies. The authors introduce SWE-Explore, a benchmark that isolates repository exploration by requiring agents to return a ranked list of relevant code regions within a fixed line budget. They derive ground truth from successful agent trajectories to evaluate coverage and ranking efficiency, demonstrating that these exploration metrics strongly track downstream repair behavior and that agentic explorers significantly outperform classical retrieval methods.
Dataset

-
Dataset Composition and Sources
- The authors construct SWE-Explore from three public repository-level benchmarks: SWE-bench Verified, SWE-bench-Pro, and SWE-bench Multilingual.
- The final benchmark contains 848 instances across 203 open-source repositories and 10 programming languages, with Python representing the largest subset due to its prevalence in the source datasets.
-
Key Details and Filtering Rules
- Each instance is retained only if at least two strong LLMs successfully resolve the original issue using the source benchmark's executable harness.
- This trajectory verification filter ensures the dataset focuses on proven repair behaviors, excluding instances that lack multiple successful solution paths.
-
Data Usage and Processing
- The authors use the dataset strictly as an evaluation benchmark to measure how coding agents explore repositories and retrieve relevant context.
- They do not apply training splits or mixture ratios, instead using the full instance set to score explorer predictions against curated ground-truth targets and run restricted-context validation.
- All file paths are canonicalized to repository-relative formats, and line intervals are standardized as 1-indexed closed ranges before evaluation.
-
Context Cropping and Metadata Construction
- Ground-truth context is derived from successful agent trajectories by extracting observable read actions, including editor view calls, command-line reads, and grep search hits.
- The authors compute a raw core context by taking the file-wise line-level intersection of reads across all successful trajectories, while optional context captures the remaining union of reads.
- An LLM-assisted refinement step promotes load-bearing optional regions that are adjacent to core evidence or repeatedly visited, followed by a strict manual audit to remove unsupported spans.
- The final refined core serves as the primary scoring target, while optional regions are reserved for diagnostics and context-efficiency analysis. Each record includes structured metadata such as instance ID, source repository, problem statement, trajectory provenance, and line-level region annotations.
Method
The authors leverage a novel benchmark framework, SWE-Explore, designed to evaluate repository-level exploration as a standalone task, decoupled from the end-to-end code repair pipeline. The core design centers on isolating the exploration phase, where an agent processes an issue and a repository snapshot to produce a ranked list of relevant code regions, denoted as P=(r1,r2,…,rK), with each region ri defined by a file path and a line range [si,ei]. This formulation, as shown in Figure 2, enables the evaluation of exploration quality independently of patch generation or verification, focusing on the accuracy and ranking of the selected code spans. The framework is structured to provide trajectory-grounded supervision, where ground truth lines are automatically derived from successful agent runs, eliminating the need for manual annotation. 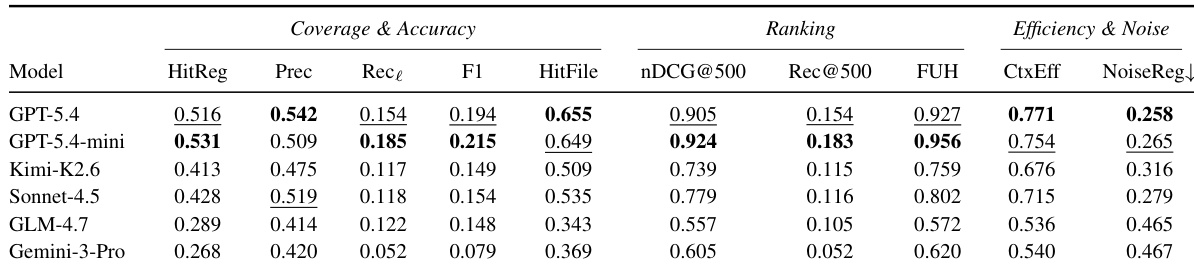
The benchmark construction process begins with the collection of solved agent trajectories from various coding agents, which are then analyzed to identify relevant code regions. This step, referred to as "Read Actions," extracts line-level interactions from the agent's execution logs. These regions are aggregated per repository file and consolidated into a "Repo-Relative Line Regions" dataset. The authors then apply a consensus aggregation process to determine high-confidence regions, labeled as Ccore, and lower-confidence regions, Copt, based on their frequency and consistency across multiple trajectories. This forms the "Trajectory-Grounded Benchmark Record," which serves as the foundation for evaluation. 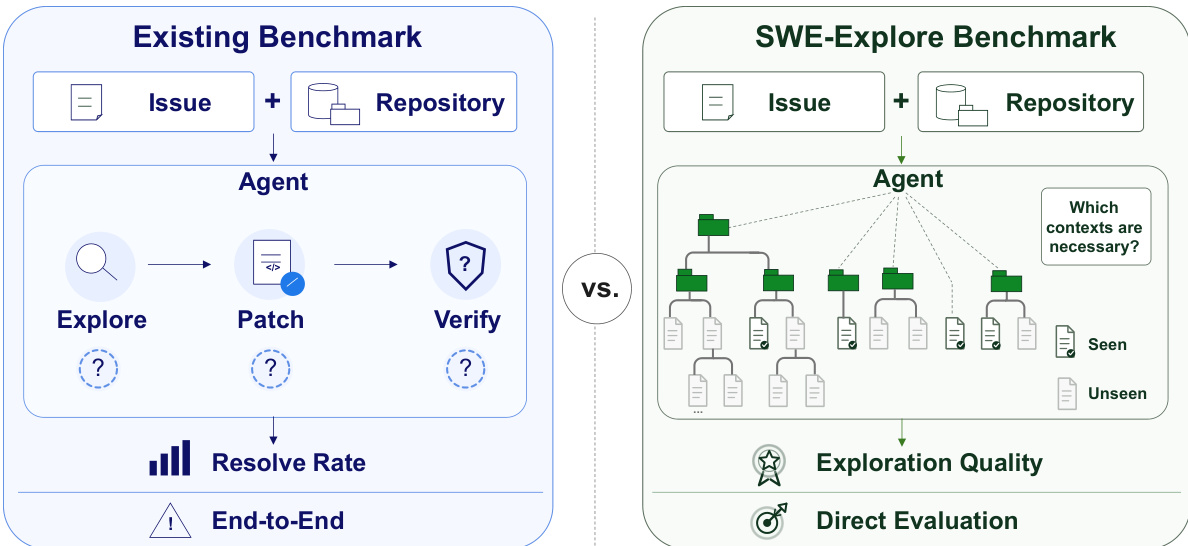
Evaluation within SWE-Explore is conducted in two parallel streams. The first stream, "Upstream Scoring," assesses the explorer's output P against the ground truth Ccore and Copt using a suite of metrics including coverage, rank@k, and utility, to measure the quality of the ranked region list. The second stream, "Restricted-Context Validation," provides a methodological validation by using the explorer's output P as the sole context for a fixed coding agent to attempt a repair, thereby linking exploration quality directly to downstream repair success. This two-pronged approach ensures that the evaluation metrics are predictive of actual repair outcomes. 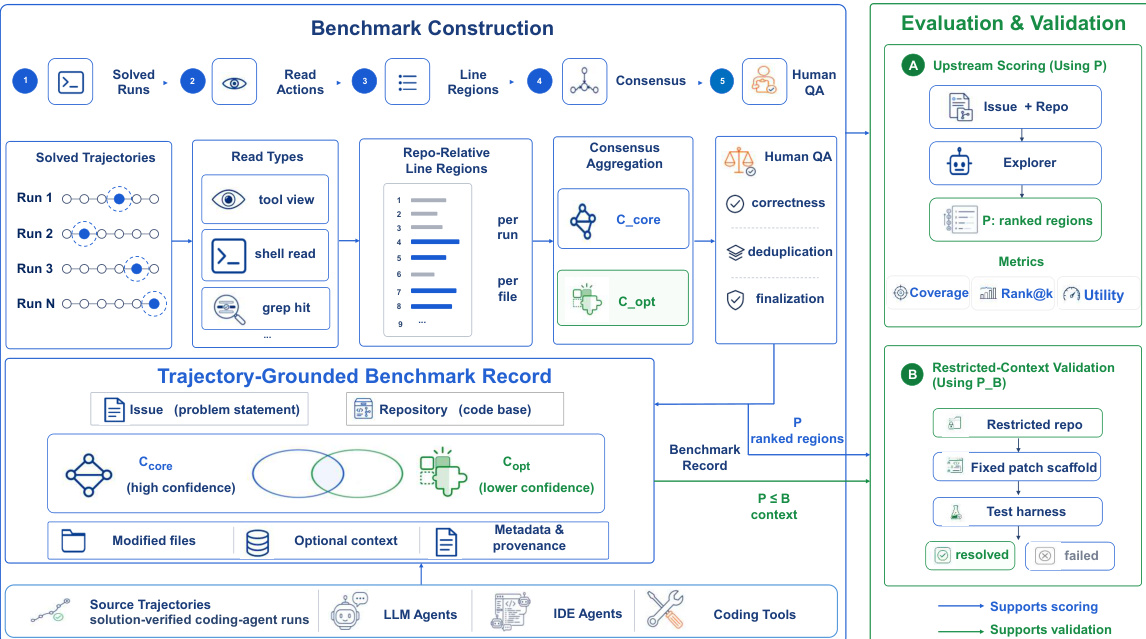
The input to the explorer consists of an issue statement and a repository snapshot, including a file tree and code views. The ground truth is derived from the lines accessed by successful agents during their problem-solving process, with each line annotated as either core or optional. The explorer's output P is a ranked list of regions, which is then scored against the ground truth using metrics such as precision at 1 and normalized discounted cumulative gain at 500 (nDCG@500). This comprehensive evaluation framework allows for the systematic comparison of different exploration strategies and their impact on code repair performance. 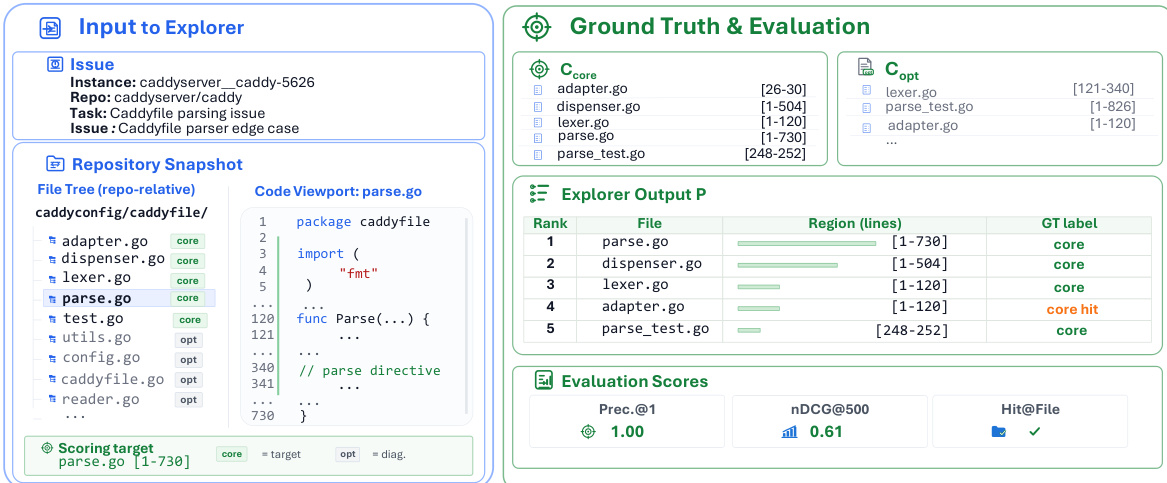
Experiment
The evaluation compares diverse retrieval and agentic explorers on a line-level repository benchmark, using a restricted-context repair environment to validate whether upstream exploration metrics reliably predict downstream patch success. Controlled degradation experiments further test system robustness by isolating the impact of missing core evidence versus redundant noise on repair outcomes. Qualitative findings indicate that while modern coding agents significantly outperform traditional baselines, they consistently struggle with line-level recall despite excelling at file-level localization. Ultimately, the results demonstrate that broad coverage and early evidence surfacing are more critical than strict precision, establishing a clear roadmap for improving repository exploration mechanisms.
The authors evaluate different models on repository exploration tasks using a set of metrics that measure coverage, ranking, and efficiency. Results show that GPT-5.4 and GPT-5.4-mini achieve the highest performance across most metrics, particularly in precision, hit rates, and ranking quality, while other models exhibit lower coverage and efficiency. The evaluation highlights the importance of both file-level and line-level accuracy, with models that achieve high file hit rates often struggling with line-level recall. GPT-5.4 and GPT-5.4-mini outperform other models in precision, hit rates, and ranking quality. Models vary significantly in coverage and efficiency, with some achieving high precision but low line-level recall. File-level hit rates are strong indicators of performance, but line-level metrics reveal critical gaps in evidence coverage.
The authors analyze the correlation between upstream exploration metrics and downstream repair performance, identifying Context Efficiency and Rec@100 as the strongest predictors of resolve rate. Metrics such as HitFile, HitRegion, and FUH also show strong correlations, while noise rates and broader recall metrics have weaker predictive power. The results suggest that efficient and early coverage of relevant evidence is more critical than precision or broad recall. Context Efficiency and Rec@100 show the strongest correlation with downstream repair success. HitFile, HitRegion, and FUH are consistently strong predictors across both correlation measures. Noise rates and broader recall metrics have weaker predictive power and are better used as diagnostics than primary success measures.
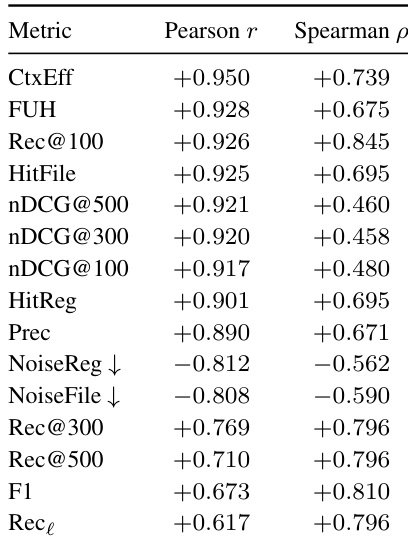
The authors evaluate various explorers using a set of metrics that measure coverage, accuracy, ranking, and efficiency. Results show that agentic explorers outperform non-agenetic retrieval methods, with general-purpose coding agents achieving high file-level hit rates and early useful evidence retrieval, while specialized localizers vary in their ability to cover relevant line-level evidence. The the the table highlights that context efficiency and first useful hit are strong indicators of downstream repair success, and that missing core evidence has a more significant negative impact than redundant context. Agentic explorers significantly outperform non-agenetic retrieval methods across coverage, ranking, and efficiency metrics. General-purpose coding agents achieve high file-level hit rates and early useful evidence retrieval, but still struggle with line-level recall. Context efficiency and first useful hit are strong predictors of downstream repair success, with missing core evidence having a more detrimental effect than redundant context.
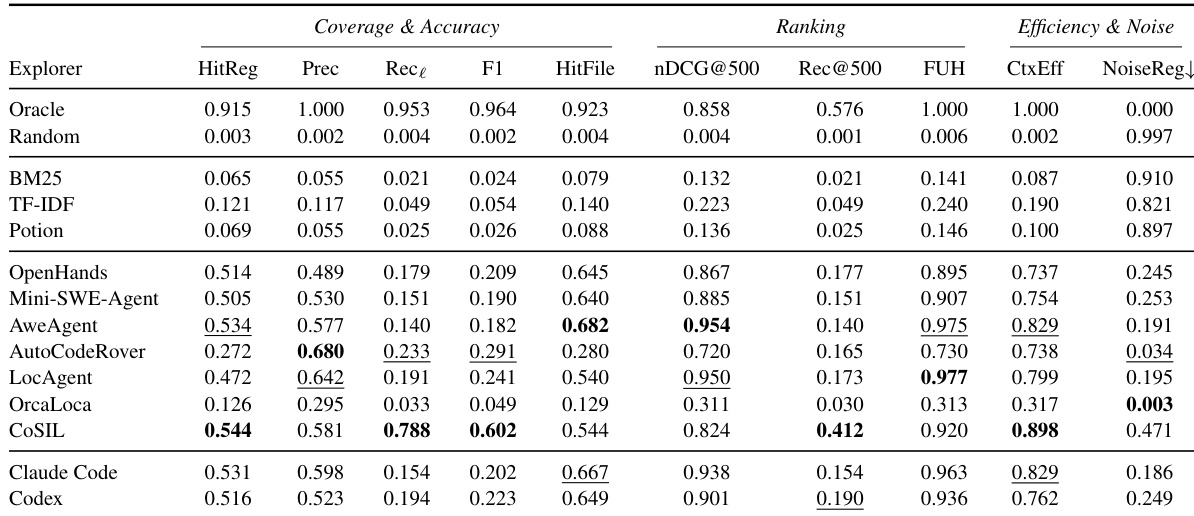
The the the table compares different benchmarks based on their support for various evaluation aspects, including execution-based, multilingual, line-level ground truth, trajectory-grounded ground truth, joint exploration and repair evaluation, and ranked region evaluation. SWE-Explore is the only benchmark that supports all five evaluation aspects, distinguishing it from others that lack one or more of these capabilities. SWE-Explore is the only benchmark that supports all five evaluation aspects: execution-based, multilingual, line-level ground truth, trajectory-grounded ground truth, and joint exploration and repair evaluation. Other benchmarks lack at least one of the evaluation aspects, with most failing to support ranked region evaluation or trajectory-grounded ground truth. SWE-Explore uniquely enables comprehensive evaluation by combining execution-based, multilingual, line-level, trajectory-grounded, and joint exploration and repair evaluation capabilities.
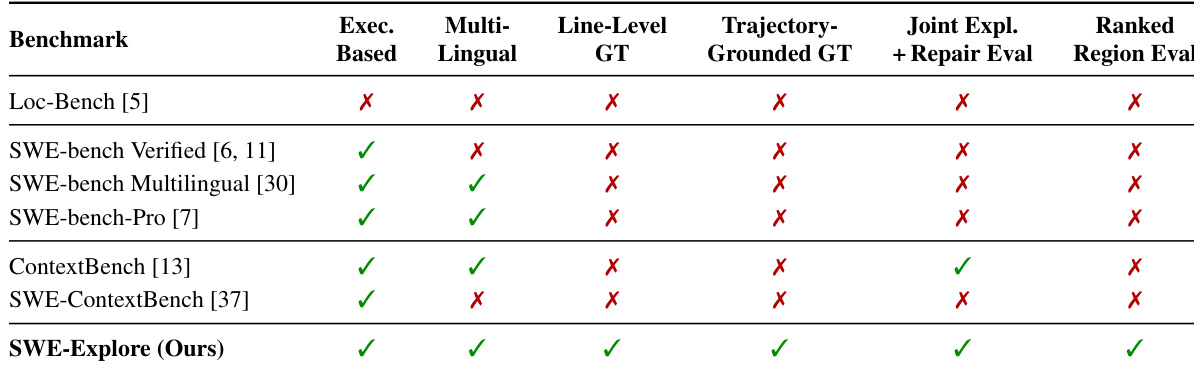
The the the table presents a comparison of different explorers in terms of their ability to return relevant code regions, with metrics such as file-level hit rate, noise, line-level recall, F1 score, and coverage. The authors evaluate explorers from various categories including retrieval-based methods, specialized localizers, and general-purpose coding agents. Results show that general-purpose agents consistently achieve high file-level hit rates and coverage, while specialized localizers often miss relevant files despite high precision on the files they do find. Retrieval-based methods perform poorly, with low hit rates and high noise. The Oracle achieves perfect scores across all metrics, serving as a benchmark for ideal performance. General-purpose coding agents achieve high file-level hit rates and coverage, indicating effective localization of relevant files and content. Specialized localizers exhibit high precision but low file-level hit rates, missing key files despite accurate predictions within the files they do identify. Retrieval-based methods like TF-IDF and BM25 perform poorly, with low hit rates and high noise, highlighting limitations in lexical search for code exploration tasks.
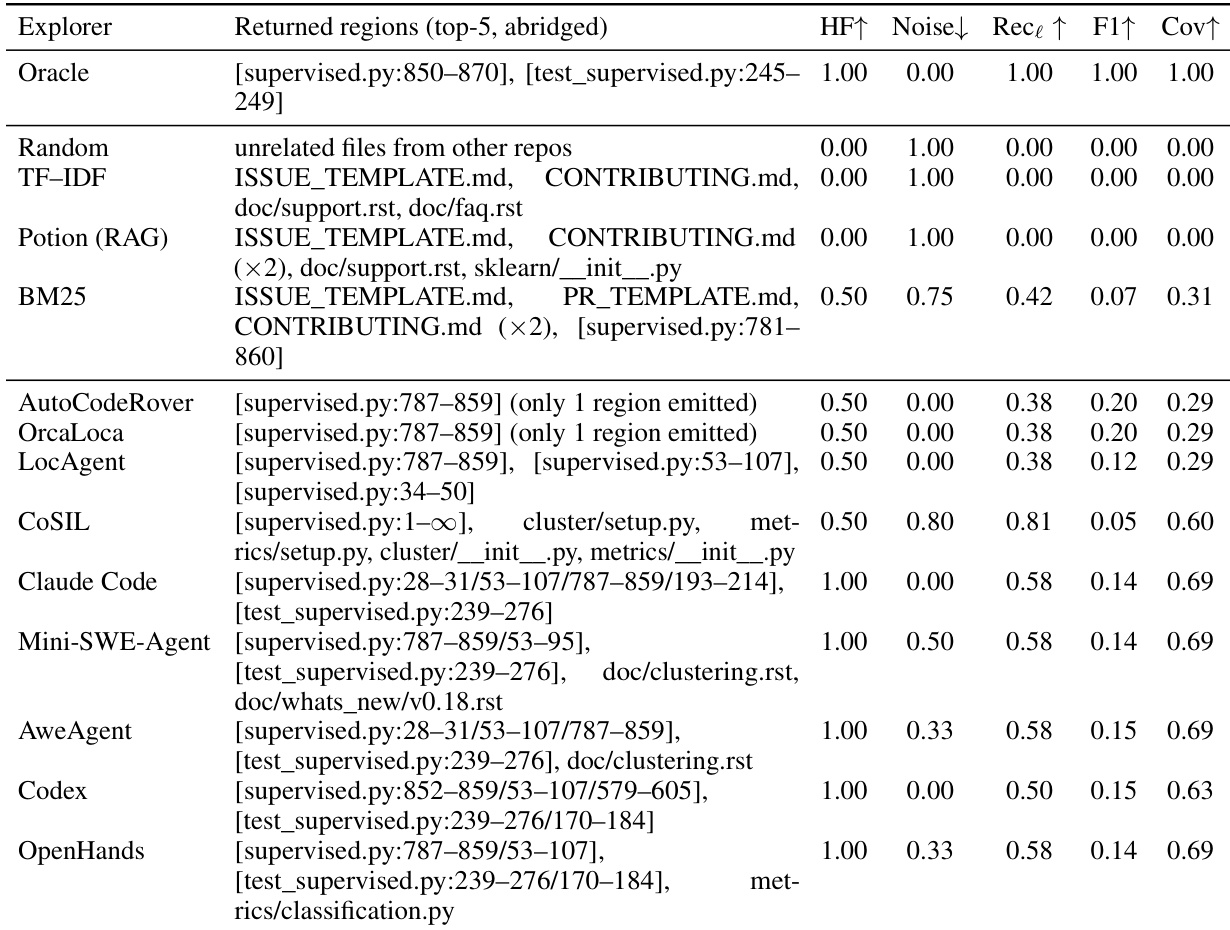
The experiments evaluate diverse repository exploration methods across coverage, ranking, and efficiency dimensions while validating how different retrieval strategies influence downstream code repair success. Qualitative analysis reveals that general-purpose coding agents and top-tier models consistently outperform specialized localizers and traditional retrieval approaches by delivering strong file-level coverage and early evidence retrieval, though line-level precision remains a persistent challenge across all techniques. Ultimately, the findings demonstrate that context efficiency and the timely identification of core evidence are far more critical for repair success than broad recall or high precision, highlighting the necessity of comprehensive benchmarks that jointly assess exploration accuracy and practical utility.