Command Palette
Search for a command to run...
MMAE: معيار ضخم متعدد المهام لتحرير الصوت
MMAE: معيار ضخم متعدد المهام لتحرير الصوت
الملخص
نقدم MMAE، وهو معيار لتحرير الصوت متعدد المهام الضخم، والذي يعمل كأول منصة تقييم شاملة مصممة خصيصاً لتحرير الصوت العام القائم على التعليمات. مدفوعاً بالتحول نحو الإنشاء الذكي، انتشر التحرير التفاعلي بسرعة من المجالات البصرية، التي سبق وأن روجت لها نماذج مثل Nano-banana 2 للصور و Gemini-Omni للفيديو، ليشمل مجال الصوت. ومع ذلك، تتخلف بنية التقييم الحالية بشكل كبير، إذ تظل مجزأة للغاية ومقيدة بمجالات فرعية محددة أو عمليات أساسية. وعلى عكس معايير التقييم الحالية المحدودة النطاق، يمتد MMAE ليشمل طيفاً واسعاً من السيناريوهات الواقعية، متضمناً 7 نماذج صوتية متميزة، تشمل الصوت والكلام والموسيقى ومزيجاتها. علاوة على ذلك، نضع تصنيفاً شاملاً يمتد على ستة مستويات من تعقيد المهمة، تتراوح من التعديلات الأساسية إلى الاستدلال متعدد الخطوات والتحرير متعدد الجولات، ومستويين للدقة، وثمانية أنواع متميزة من العمليات. وقد تم انتقاؤه بعناية فائقة من خلال التعاون بين الإنسان والـ agent، ويتضمن MMAE ألفين من العينات عالية الدقة، مقترنة بإطار تقييم رائد قائم على المعايير. ومن خلال تفكيك المهام ذات الصيغة الحرة إلى 17,741 معياراً قابلاً للتحقق، يتيح هذا النموذج القوي القائم على المعايير تقييماً دقيقاً ومتعدد الأبعاد لكل من الالتزام بالتعليمات واتساق السياق. ويكشف تقييمنا الشامل للنماذج الرائدة أن الأنظمة الحالية لا تزال بعيدة عن تحقيق عمليات تحرير موثوقة. وبشكل لافت للنظر، ينخفض معدل التطابق الدقيق (EMR) باستمرار دون 5٪، ويهبط إلى 0٪ تماماً في المهام المعقدة والمختلطة النماذج، مما يكشف عن اختناقات حرجة في التنفيذ الدقيق والمتانة الهيكلية. ونأمل أن يعمل MMAE كحافز للتقدم المستقبلي في مجتمع الإنشاء الذكي، من خلال توفير خارطة طريق تشخيصية واضحة، وإرساء نموذج تقييم موحد ومستدام لأنظمة تحرير الصوت من الجيل التالي.
One-sentence Summary
the paper introduce MMAE, a massive multitask audio editing benchmark that addresses the fragmentation of existing evaluations by establishing a comprehensive taxonomy across seven audio modalities and six complexity levels, while employing a rubric-based framework that decomposes 2,000 curated samples into 17,741 verifiable criteria to precisely assess instruction following and context consistency in general-purpose audio editing models.
Key Contributions
- Introduces MMAE, a comprehensive benchmark for instruction-based audio editing that spans 7 distinct modalities and 8 operation categories across multiple complexity levels. Meticulously curated via a human-agent collaboration pipeline, the dataset comprises 2,000 high-fidelity samples designed to evaluate real-world editing scenarios.
- Establishes a novel rubric-based evaluation framework that decomposes free-form editing instructions into 17,741 verifiable criteria. This structured paradigm enables precise, multi-dimensional assessment of instruction following and acoustic context consistency to maximize diagnostic reliability.
- Evaluates 5 state-of-the-art audio editing models to reveal that existing systems struggle with context preservation and structural robustness, with exact match rates consistently falling below 5 percent. Detailed analysis identifies critical bottlenecks in model understanding and generation that intensify as task complexity increases.
Introduction
Instruction-based audio editing has rapidly matured into a practical creative tool, enabling users to manipulate speech, music, and sound effects through natural language commands. Despite this progress, the field suffers from a critical evaluation gap, as existing benchmarks remain fragmented across narrow domains and rely on coarse metrics that cannot accurately assess complex, open-ended editing workflows. To bridge this divide, the authors introduce MMAE, a comprehensive benchmark designed to rigorously evaluate general-purpose audio editing models. They leverage a meticulously curated dataset spanning seven audio modalities and six task complexity levels, paired with a novel rubric-based evaluation paradigm that breaks down free-form instructions into structured, verifiable criteria. This framework delivers fine-grained, multi-dimensional scoring that reliably diagnoses model capabilities, establishing a standardized foundation for advancing the next generation of interactive audio systems.
Dataset

-
Dataset Composition and Sources The authors introduce MMAE, a benchmark comprising 2,000 high-fidelity audio samples collected from online videos. Each sample is paired with open-ended natural language instructions and over 17,741 fine-grained evaluation rubrics. The dataset spans seven distinct audio modalities, including sound, music, speech, and their various combinations.
-
Key Details and Taxonomy Breakdown The dataset is organized across three orthogonal dimensions to ensure comprehensive coverage. The modality dimension covers the seven audio types mentioned above. The complexity dimension stratifies tasks into six levels, ranging from basic single operations to multi-hop reasoning and multi-round iterative editing. The operation dimension categorizes edits by granularity into local modifications targeting specific segments and global adjustments affecting the entire track. The authors applied a dynamic balancing strategy to maintain even distribution across these taxonomy dimensions. Statistically, each sample averages 14.46 seconds in duration, contains 1.22 editing operations, and is guided by a 14-word instruction. The rubric collection averages 8.87 criteria per sample, split between instruction following and consistency checks.
-
Benchmark Usage and Evaluation Strategy Unlike training corpora, MMAE is designed exclusively for evaluation. The authors use the dataset to assess the instruction-following accuracy and contextual preservation of state-of-the-art audio editing models. They bypass traditional signal-level metrics in favor of a rubric-based evaluation framework. Each sample is scored by an external audio language model that acts as a judge, selecting the correct option from atomic, multiple-choice criteria that verify precise execution and background preservation.
-
Processing, Cropping, and Metadata Construction Raw audio is manually sourced from online videos and trimmed into focused input clips. The authors structure all annotations as JSON objects containing identifiers, taxonomy labels, operation details, user prompts, and descriptive tags. Data curation follows a five-stage pipeline that begins with expert brainstorming and taxonomy design, moves to instruction-centric collection, and proceeds to human-agent collaborative rubric generation. An agentic system extracts detailed audio captions that feed into an LLM for initial criterion drafting, which human annotators then refine. The authors enforce strict quality control through a blind cross-review protocol that iteratively revises or discards samples that fail acceptance criteria.
Method
The authors leverage a multi-stage pipeline for constructing and evaluating audio manipulation tasks, beginning with brainstorming and culminating in quality assurance. The process starts with idea generation, where diverse audio manipulation concepts—such as background music extraction, speech enhancement, and sound replacement—are explored. This phase is followed by taxonomy and paradigm construction, in which the collected ideas are organized into a structured framework based on key attributes including modality, operation, complexity, dimension, and metrics. As shown in the figure below, this structured taxonomy enables the systematic classification of tasks into distinct paradigms.
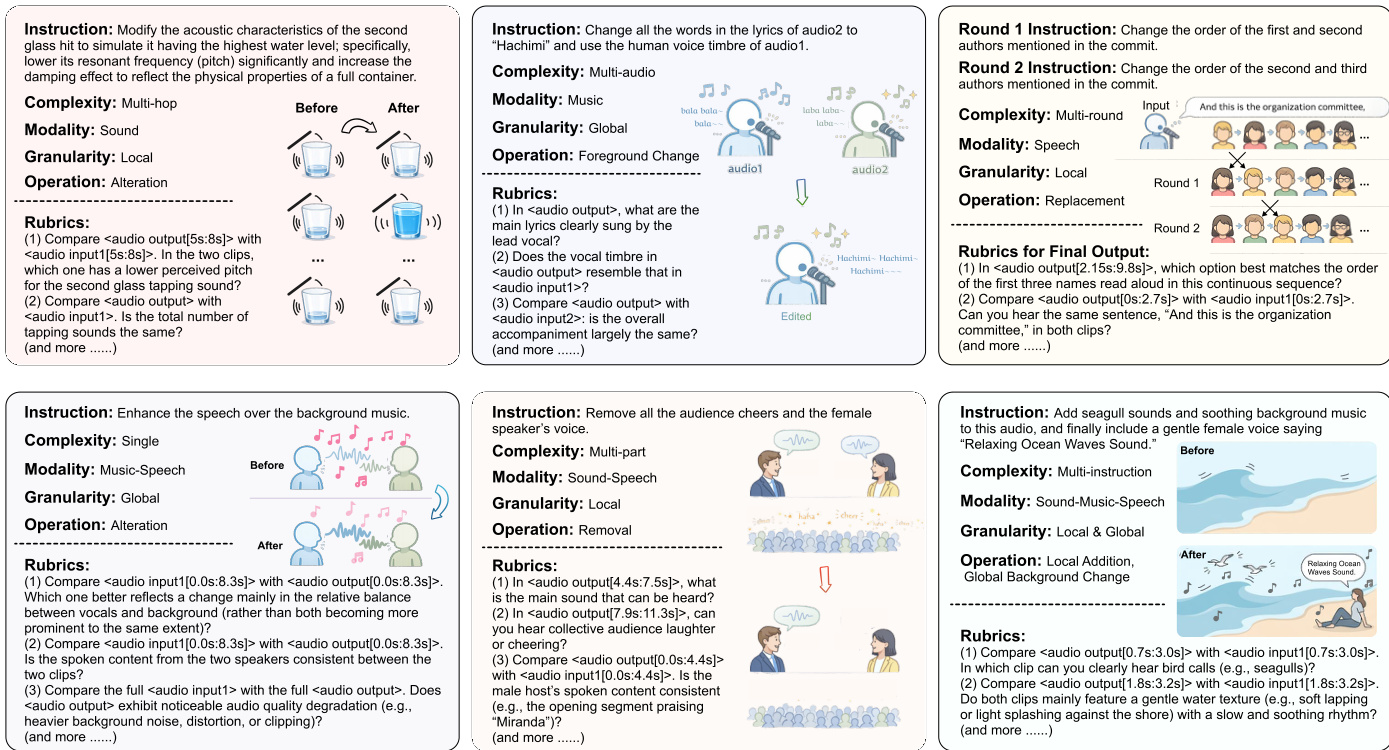
The framework proceeds to instruction-centric data collection, where source media—including speech, sound, and music—are selected and processed. Raw audio and video inputs undergo trimming and annotation to produce structured data. This data is then used to generate instructions that define specific audio manipulation tasks, such as altering the order of speakers, modifying acoustic properties, or enhancing speech over background noise. Each task is annotated with rubrics that guide evaluation, ensuring consistency in assessing the quality of generated outputs.
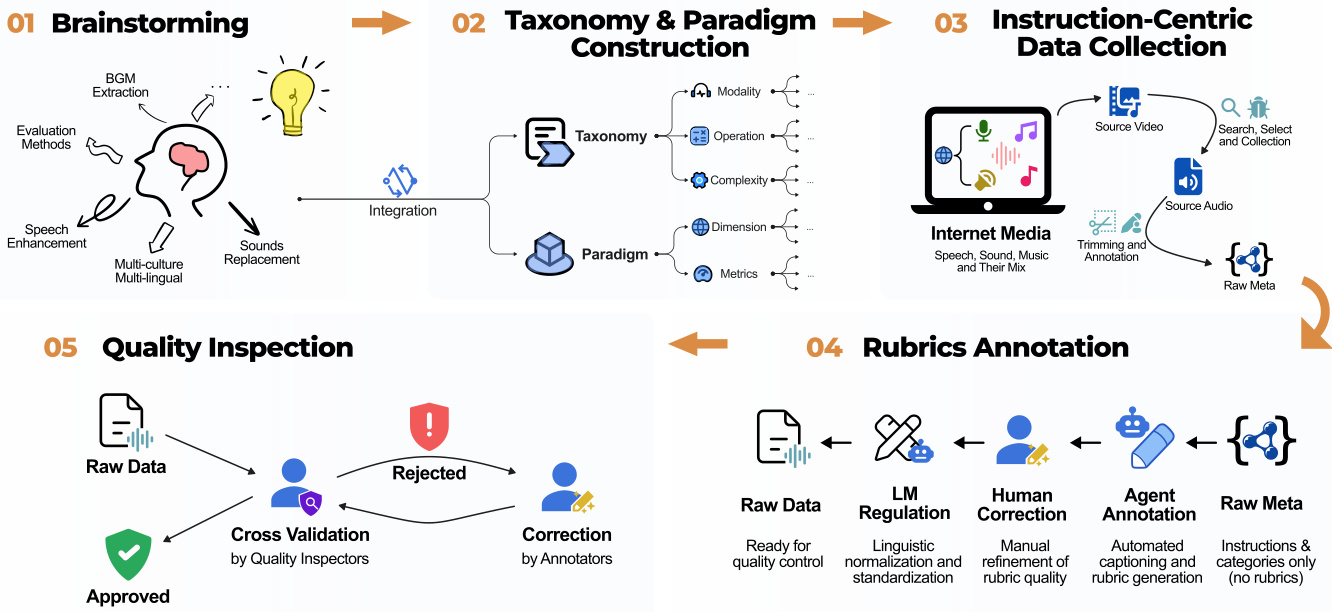
The data collection process includes a rubric annotation stage, where raw metadata is refined through automated captioning and manual correction. This produces high-quality, rubric-enabled instructions suitable for evaluation. The final stage involves quality inspection, where raw data is cross-validated by human annotators. Data that fails to meet quality standards is rejected, while approved data is prepared for downstream use. This rigorous pipeline ensures that the resulting audio manipulation tasks are well-defined, consistent, and suitable for evaluation by large language models.
Experiment
The study evaluates five recent end-to-end audio editing models on the MMAE benchmark using an LLM-based judge and reference baselines to assess instruction following, content consistency, and exact match rates. The experiments demonstrate that current systems struggle with complex and mixed-modality tasks, revealing a fundamental trade-off between executing precise modifications and preserving original audio. Additionally, average performance scores do not guarantee flawless execution, and external planning mechanisms yield limited improvements due to cascading comprehension and generation errors. These findings indicate that while basic editing capabilities exist, achieving reliable audio manipulation requires stronger foundational models rather than reliance on high-level task decomposition.
The authors evaluate several audio editing models on the MMAE benchmark, focusing on instruction following, consistency, and exact match rates. Results show that all models struggle with complex and mixed-modality tasks, exhibiting a trade-off between instruction adherence and content preservation, with no model achieving high exact match rates. The best-performing model shows strong instruction following and consistency in single-modality tasks but still fails to achieve flawless edits in most cases. All models exhibit a performance drop when transitioning from single to multiple complexity tasks, with mixed-modality editing proving particularly challenging. There is a clear trade-off between instruction following and consistency, as demonstrated by the baselines and evaluated models. The best model achieves high average scores in instruction following and consistency but still shows low exact match rates, indicating a gap between partial success and flawless execution.
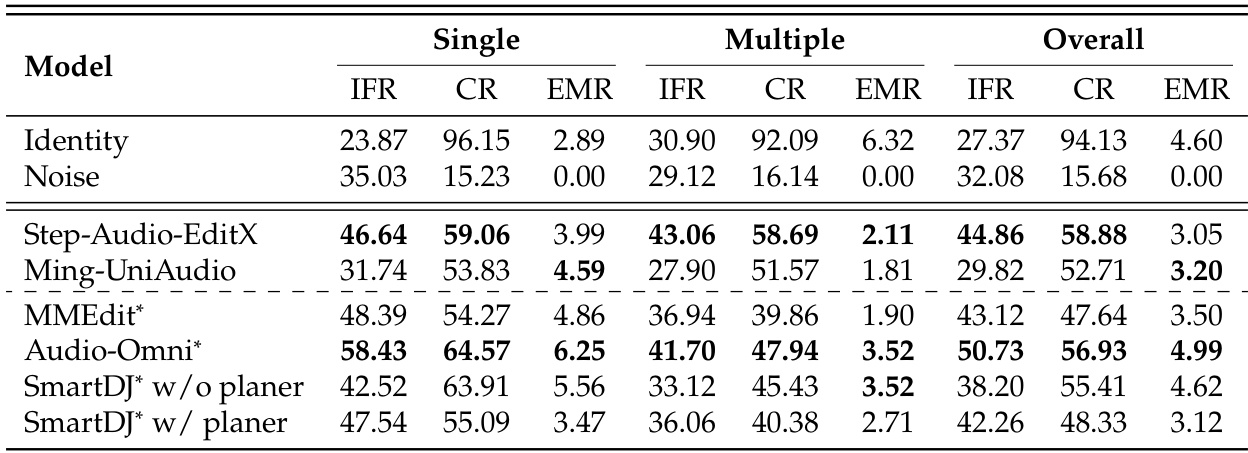
The authors evaluate several audio editing models on the MMAE benchmark, comparing their performance across different modalities and task complexities. Results show that all models struggle with mixed-modality tasks and exhibit a trade-off between instruction following and consistency, with most achieving low exact match rates. The best-performing models show varying strengths across sound, music, and speech domains, and the use of an external planner does not consistently improve overall performance. All models show significant performance drops on mixed-modality tasks compared to single-modality editing. There is a trade-off between instruction following and consistency, with reference baselines highlighting the difficulty of achieving both simultaneously. Performance varies across modalities, with speech editing generally yielding higher consistency scores than sound and music editing.
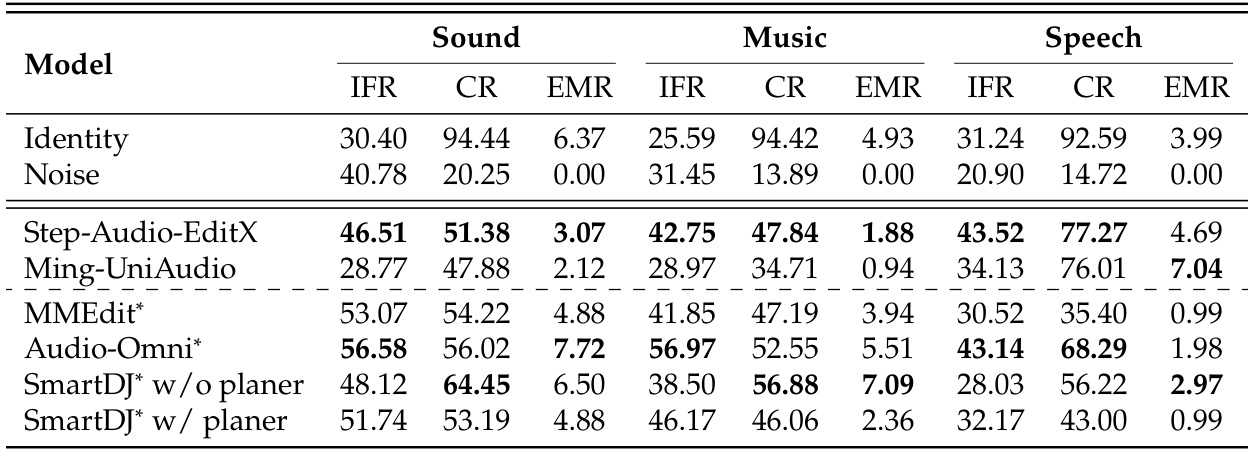
The authors evaluate multiple audio editing models on a benchmark that assesses instruction following, consistency, and exact match rates. Results show that all models struggle with complex and mixed-modality tasks, exhibiting a trade-off between instruction adherence and content preservation, with few achieving flawless edits. The performance gap between average competency and perfect execution rates suggests that models often make partial progress rather than fully satisfying all requirements. All models show significant performance degradation on complex and mixed-modality tasks, indicating limited structural robustness for multi-domain editing. There is a clear trade-off between instruction following and consistency, with models excelling in one often failing in the other, highlighting the difficulty of balancing precise modifications with content preservation. Average performance metrics do not align with exact match rates, revealing that models may achieve broad competence while frequently failing to produce perfect edits, suggesting a gap between general capability and holistic reliability.

The authors evaluate several audio editing models on a benchmark that assesses instruction following, consistency, and exact match rates across different modalities and complexity levels. Results show that all models struggle with mixed-modality tasks and exhibit a trade-off between following instructions and preserving content, with no model achieving high exact match rates. Performance varies significantly by task type, and the use of an external planner does not consistently improve outcomes. All models perform significantly worse on mixed-modality tasks compared to single-modality ones. There is a clear trade-off between instruction following and consistency, with models excelling in one often failing in the other. The use of an external planner does not lead to consistent improvements, as it can degrade audio consistency despite slightly improving instruction adherence.
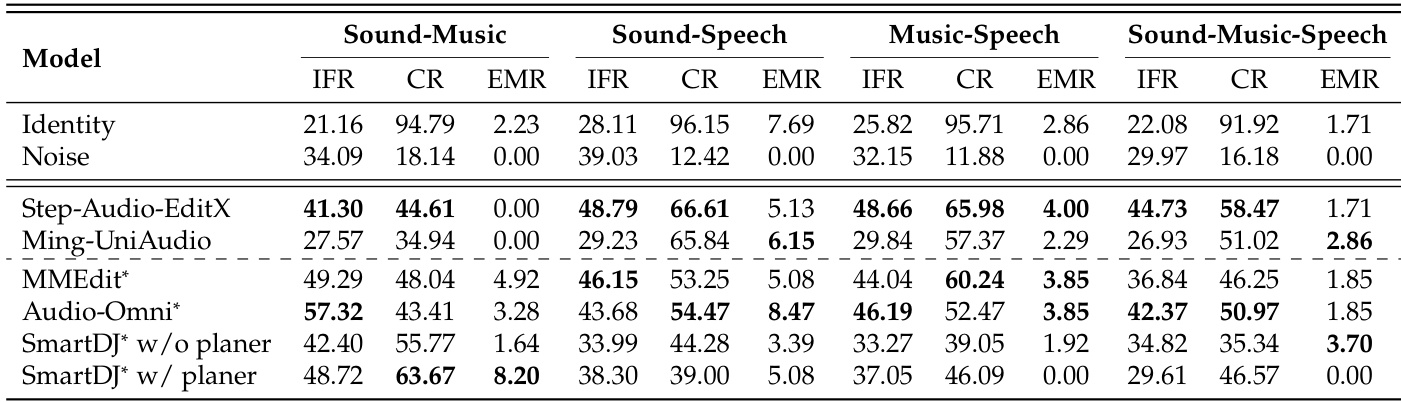
The authors evaluate several audio editing models on the MMAE benchmark, assessing their ability to follow instructions and maintain consistency across different task complexities and modalities. Results show that all models struggle with perfect editing, exhibiting low exact match rates and a trade-off between instruction following and consistency, with performance degrading significantly in mixed-modality and complex tasks. All models show significant performance degradation when moving from single to multiple task categories, indicating challenges with complex editing scenarios. There is a clear trade-off between instruction following and consistency, where models that follow instructions better often fail to preserve content, and vice versa. Performance in mixed-modality tasks is consistently lower than in single-modality settings, with sound-music-speech tasks being the most difficult across all models.

The authors evaluate multiple audio editing models on the MMAE benchmark to assess instruction following, content consistency, and exact match rates across varying task complexities and modalities. Results reveal a persistent trade-off between adhering to prompts and preserving audio integrity, with all models experiencing significant performance degradation on mixed-modality and complex tasks. While some models demonstrate partial success, the consistently low exact match rates highlight a substantial gap between general competence and flawless execution. Ultimately, the findings underscore current limitations in multi-domain structural robustness and indicate that external planning mechanisms do not reliably improve holistic editing outcomes.