Command Palette
Search for a command to run...
التقرير الفني الخاص بـ LongCat-Video-Avatar 1.5
التقرير الفني الخاص بـ LongCat-Video-Avatar 1.5
Meituan LongCat Team
نموذج الشخصيات الرقمية LongCat-Video-Avatar 1.5
الملخص
على الرغم من التقدم المحرز في مجال توليد الفيديو المدفوع بالصوت، لا يزال تحقيق الاستقرار على المستوى التجاري أمراً يمثل تحدياً كبيراً. نقدم هنا LongCat-Video-Avatar 1.5، وهو إطار عمل مفتوح المصدر مطوّر، يضع أولوية قصوى للهندسة المنهجية والجاهزية للإنتاج بدلاً من التركيز على الابتكارات المعمارية. ومن خلال ترقية مُشفّر الصوت إلى Whisper Large، والحرص الدقيق على توسيع نطاق وصفات التدريب الخاصة بنا، يحقق الإصدار 1.5 مزامنة شفاه دقيقة، واستقراراً زمنياً للجسم بأكمله، وقدرة قوية على توليد مقاطع فيديو طويلة مع الحفاظ على تجانس الهوية بدقة.وبفضل العناية الصارمة باختيار البيانات وتدريب النماذج باستخدام تعزيز التعلم من التغذية الراجعة البشرية (RLHF Training)، تتعمم هذه النماذج بسهولة في المجالات الأسلوبية مثل الأنيمال والحيوانات، كما تتعامل بشكل أصلي مع الظروف المعقدة في العالم الحقيقي، مثل التفاعلات متعددة الأشخاص والتعامل مع الأشياء. علاوة على ذلك، استجابةً للمتطلبات العملية للنشر الصناعي، قمنا بتوظيف تقنية تنقيص الخطوات المتقدمة (step distillation) لتسريع الاستدلال إلى 8 خطوات (NFE)، مما يحقق توازناً مثالياً بين كفاءة الخادم ودقة المخرجات البصرية.وقد تم التحقق من تفوق نهجنا من خلال مجموعة شاملة من المقاييس الكمية وتقييم بشري صارم أُجري على أساس تقييمي شامل يضم أكثر من 500 حالة اختبار متنوعة. تظهر النتائج أن الإصدار 1.5 achieves أداءً تنافسياً أو متفوقاً مقارنةً بأبرز الأنظمة مغلقة المصدر (مثل HeyGen، وOmniHuman 1.5، وKling Avatar 2.0) في معايير تشابه الإنسان والتقييمات النوعية على مستوى الخبراء ضمن الأساس التقييمي المعتمد. ومع طرحه كمصدر مفتوح، يسهم LongCat-Video-Avatar 1.5 في سد الفجوة بين النماذج الأولية البحثية الأكاديمية ونشر المنتجات على المستوى التجاري.
One-sentence Summary
Meituan LongCat Team presents LongCat-Video-Avatar 1.5, an open-source framework prioritizing production readiness for audio-driven video generation that integrates Whisper Large audio encoders, RLHF training, and step distillation to accelerate inference to 8 NFE while ensuring accurate lip-synchronization, full-body temporal stability, and strict identity consistency across stylized and real-world domains, validated through rigorous human evaluation on over 500 diverse test cases where it demonstrates competitive or superior performance against leading closed-source systems such as HeyGen, OmniHuman 1.5, and Kling Avatar 2.0, ultimately narrowing the gap between academic research prototypes and commercial-grade deployment.
Key Contributions
- The paper presents LongCat-Video-Avatar 1.5, an open-source framework designed for commercial-grade stability in audio-driven video generation. Upgrading the audio encoder to Whisper Large and scaling training recipes enables accurate lip-synchronization and strict identity consistency in long videos.
- Advanced step distillation is employed to accelerate inference to an optimal 8 NFE, balancing serving efficiency with visual fidelity. Group-Relative Policy Optimization is further integrated to enhance generation quality and generalization to stylized domains.
- Rigorous validation is provided through extensive quantitative metrics and human evaluation on a comprehensive benchmark of over 500 diverse test cases. The model demonstrates competitive or superior performance against leading closed-source systems across human-likeness and expert-level quality assessments.
Introduction
Audio-driven human animation is essential for digital humans and virtual communication, yet achieving commercial-grade stability remains a significant hurdle. Existing models often struggle with long-horizon identity consistency and robustness in complex scenarios like multi-person interactions or object handling. The authors present LongCat-Video-Avatar 1.5, an open-source framework designed to bridge the gap between academic prototypes and production-ready systems. They leverage an upgraded Whisper Large audio encoder to improve lip synchronization and employ Group-Relative Policy Optimization to align generation quality with human preferences. Additionally, the team implements advanced step distillation to accelerate inference to just 8 NFEs while maintaining visual fidelity. This systematic engineering approach enables the model to outperform leading closed-source systems in naturalness and stability across diverse benchmarks.
Dataset
- The authors construct a multi-stage general data pipeline to support stable and controllable single-person avatar generation.
- Raw videos are organized by functional contribution across six categories including close-up face, interview, acted performance, interaction, music, and animation.
- A unified annotation schema maps heterogeneous videos into a reusable representation space covering human structure, audio quality, and visual artifacts.
- Offline annotation precomputes stable attributes such as face location and lip synchronization confidence to enable content-based selection.
- Online validation performs clip-level quality control to filter duration, brightness, and motion consistency before training inputs are finalized.
- Three specialized pipelines address specific challenges beyond the general framework to improve generation quality.
- Multi-person data utilizes ByteTrack and Active Speaker Detection to isolate non-overlapping single-speaker segments and exclude concurrent activity.
- Silent data requires consensus between Qwen3-Omni and Qwen3-VL models to confirm non-speaking states across all clips in a video.
- Emotion data follows a six-category taxonomy refined by EmotiEffLib with a confidence threshold greater than 0.7.
- Hard exclusion rules remove synthetic content or videos with multiple subjects from the emotion subset.
- Context-aware annotations describe spatial environment and physical movement evolution objectively for the emotion subset.
- Structured metadata is converted into textual conditions that include camera behavior and visual style alongside content descriptions.
- Training stages select samples based on task-specific attributes like body composition or lip visibility rather than coarse source rules.
- This approach enables the model to learn relationships among semantic content, human motion, and camera language through interpretable filtering.
Method
The authors leverage a unified DiT-based video diffusion architecture, inheriting the foundation from LongCat-Video-Avatar 1.0. The model is constructed upon a 3D Variational Autoencoder (VAE), where each Diffusion Transformer (DiT) block integrates 3D self-attention, text cross-attention, and a Feed-Forward Network (FFN). Text embeddings are processed via a UMT5 encoder, while 3D Rotary Position Embeddings (RoPE) are applied to visual tokens to capture spatiotemporal positional information. The complete network architecture is illustrated below.
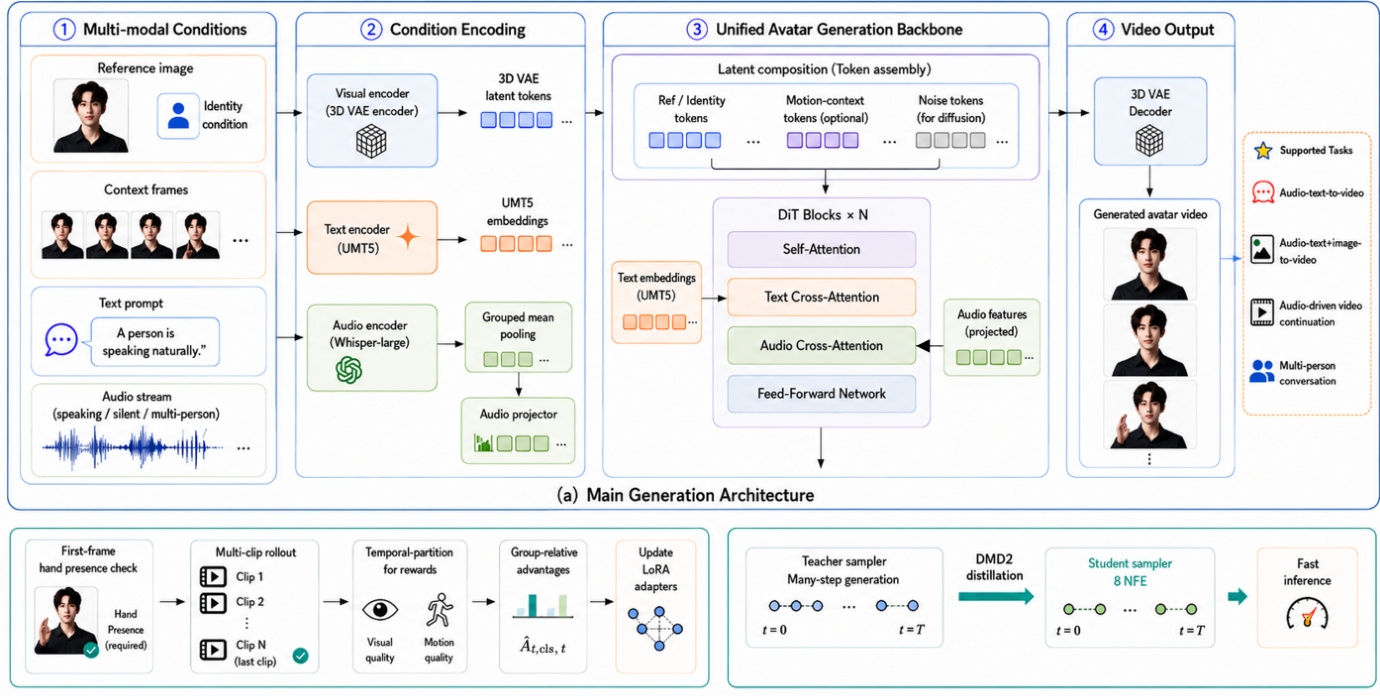
The unified architecture supports multiple audio-driven human animation tasks through flexible input configurations. The network accepts three types of latent sequences: reference latents for identity, motion latents for context, and noise latents for generation. For text-to-video tasks, only noise latents are provided. For text-image-to-video generation, the reference latent is temporally concatenated with noise latents. For video continuation, context latents are concatenated with noise latents to serve as conditioning signals. To enable audio-driven generation, an additional audio cross-attention layer is inserted after the text cross-attention module within each DiT block. An Adaptive Layer Normalization (adaLN) module precedes this layer to function as a gating mechanism, ensuring stable optimization and preventing catastrophic forgetting of visual priors while aligning audio signals with mouth movements.
For audio feature extraction, the system upgrades from Wav2Vec2 to Whisper-large, leveraging its 1.5B parameters and multilingual robustness. To handle audio streams exceeding the 30-second context limit, a sliding window strategy partitions the input spectrogram. The resulting hidden states undergo grouped mean pooling to compress the representation into a compact 5-channel feature set. These features are temporally resampled to 25 FPS and passed through an audio projector to match the video latent sequence length, ensuring strict temporal alignment.
The training pipeline consists of three progressive stages: Base Model Training, RLHF Training, and Acceleration Training. Base Model Training utilizes a flow matching framework to synthesize temporally coherent and identity-preserving video conditioned on speech. This stage progresses from low-resolution pretraining to high-resolution synthesis, followed by the introduction of reference images for identity preservation and multi-person dialogue datasets for conversational scenarios.
Following base training, the model undergoes Reinforcement Learning from Human Feedback (RLHF) using Group-Relative Policy Optimization (GRPO). This approach shifts from video-level to per-frame reward modeling, decomposing rewards along temporal partitions. The effective relative advantage is calculated as a weighted sum of individual relative advantages, allowing for finer-grained credit assignment to address local motion inconsistencies or structural collapse. The training also incorporates a first-frame hand-presence check and a multi-clip rollout strategy to support long-horizon video continuation.
Finally, Acceleration Training employs Distribution Matching Distillation 2 (DMD2) to distill the multi-step diffusion model into an efficient few-step generator. To overcome VRAM bottlenecks, a parameter-efficient architecture is used where a single base DiT backbone is equipped with multiple LoRA adapters (Generator and Fake Score). The model is distilled to 8 denoising steps, balancing inference speed with generation quality. For multi-person conversations, the L-RoPE mechanism associates specific speaker regions with their audio conditions, while a silent audio track is assigned to background characters to prevent unintended lip movements.
Experiment
The study establishes a human evaluation benchmark comprising 508 image and audio pairs to assess virtual human generation across dimensions such as rationality and harmony. Qualitative results indicate that the proposed LC-Video-Avatar 1.5 model achieves superior stability and identity preservation compared to state-of-the-art methods, although physical rationality and synchronization gaps persist across the industry. Additionally, comparisons between the base and accelerated versions highlight a trade-off where the faster variant prioritizes visual stability while the base model offers greater motion diversity and lip alignment accuracy.
The the the table compares a standard Base model against an accelerated Fast variant, revealing a distinct trade-off between expressive richness and generation stability. While the Base model achieves slightly higher human-likeness scores in single-person scenarios and better audio-visual harmony, the Fast variant significantly outperforms it in stability and physical rationality metrics. The Fast model demonstrates significantly lower issue rates in stability and rationality compared to the Base model. The Base model retains a slight advantage in single-person human-likeness scores and harmony metrics. Multi-person human-likeness scores are marginally higher for the Fast variant compared to the Base model.

This experiment evaluates a standard Base model against an accelerated Fast variant to highlight the trade-off between expressive richness and generation stability. The Base model retains a slight edge in single-person human-likeness and audio-visual harmony, whereas the Fast variant significantly outperforms it in stability and physical rationality with fewer issues. Furthermore, the Fast model achieves marginally higher multi-person human-likeness scores, indicating its effectiveness in more complex interactions.