Command Palette
Search for a command to run...
π-Bench: تقييم وكلاء المساعدين الشخصيين الاستباقيين في سير العمل طويل المدى
π-Bench: تقييم وكلاء المساعدين الشخصيين الاستباقيين في سير العمل طويل المدى
الملخص
عنوان:ملخص: تسلط ظهور وكلاء المساعدين الشخصيين، مثل OpenClaw، الضوء على الإمكانات المتزايدة لنماذج اللغات الكبيرة في دعم المستخدمين في حياتهم اليومية وعملهم. تتمثل إحدى التحديات الأساسية في هذه السياقات في تقديم المساعدة الاستباقية، إذ غالباً ما يبدأ المستخدمون بطلبات غير محددة بوضوح، ويتركون احتياجاتاً أو قيوداً أو تفضيلاتاً مهمة دون ذكر صريح. ومع ذلك، نادراً ما تقيّم المنصات المعيارية الحالية ما إذا كانت الوكلاء قادرون على تحديد النوايا الخفية والعمل عليها قبل أن يُصرّح بها صراحةً، لا سيما في التفاعلات متعددة الأدوار المستمرة حيث تظهر احتياجات المستخدم تدريجياً. ولتسديده هذا الفجوة، نقدم π-Bench، وهو معيار للمساعدة الاستباقية يتألف من 100 مهمة متعددة الأدوار عبر 5 شخصيات مستخدمين محددة بالنطاق. ومن خلال دمج النوايا الخفية للمستخدمين، والتبعيات بين المهام، والاستمرارية عبر الجلسات، يقيّم π-Bench قدرة الوكلاء على توقع احتياجات المستخدمين ومعالجتها على مدى تفاعلات ممتدة، مقاساً بشكل مشترك الاستباقية وإكمال المهام في مسارات طويلة الأمد تعكس بشكل أفضل الاستخدام الواقعي. تُظهر التجارب أن (1) المساعدة الاستباقية لا تزال تمثل تحدياً، (2) هناك تمييز واضح بين إكمال المهام والاستباقية، و(3) قيمة التفاعل السابق في حل النوايا الاستباقية في المهام اللاحقة.
One-sentence Summary
The authors introduce π-BENCH, a benchmark comprising 100 multi-turn tasks across five personas that evaluates proactive personal assistant agents through hidden intents, inter-task dependencies, and cross-session continuity, ultimately revealing a clear distinction between proactive assistance and task completion in long-horizon workflows.
Key Contributions
- The paper formalizes proactive assistance for long-horizon personal agents by establishing evaluation criteria that measure how systems anticipate and address underspecified user needs across extended, multi-session interactions.
- The work introduces π-BENCH, a benchmark comprising 100 multi-turn tasks across five domain-specific personas that jointly evaluates proactivity and task completion via agent trajectories featuring long-range, cross-session dependencies.
- Experiments demonstrate that proactive assistance remains challenging for frontier models, reveal a clear distinction between task completion and proactivity, and show that prior interaction history improves intent resolution in later tasks.
Introduction
The authors tackle the shift toward long-horizon personal assistant agents that operate across persistent workspaces and multi-session workflows. In practice, users rarely provide complete task specifications, so assistants must proactively infer hidden preferences and constraints from interaction history to reduce cognitive load and deliver coherent results. Existing benchmarks struggle with this reality because they typically assume explicit goals, focus on short-horizon mobile tasks, or treat memory as a simple retrieval tool rather than a mechanism for detecting underspecified requirements. To address these limitations, the authors introduce π-BENCH, a benchmark designed to evaluate proactive assistance through 100 multi-turn tasks with cross-session dependencies. Their experiments demonstrate that while frontier models can complete tasks, they consistently fall short in anticipating hidden intents, highlighting a critical gap between raw task completion and genuinely reducing user effort.
Dataset
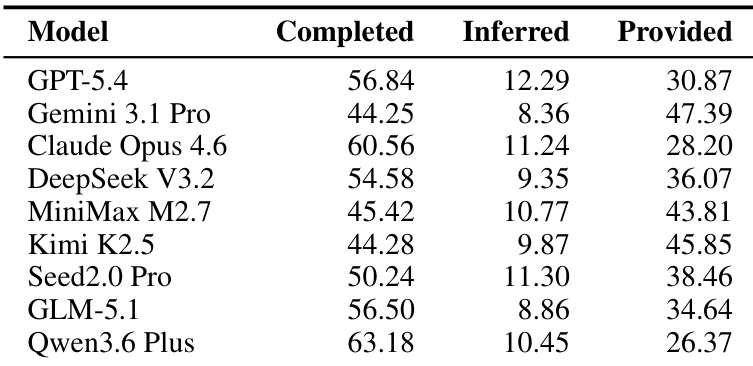
-
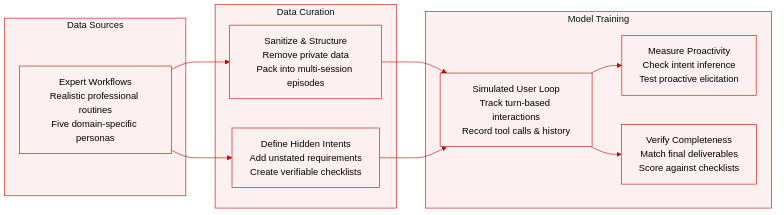
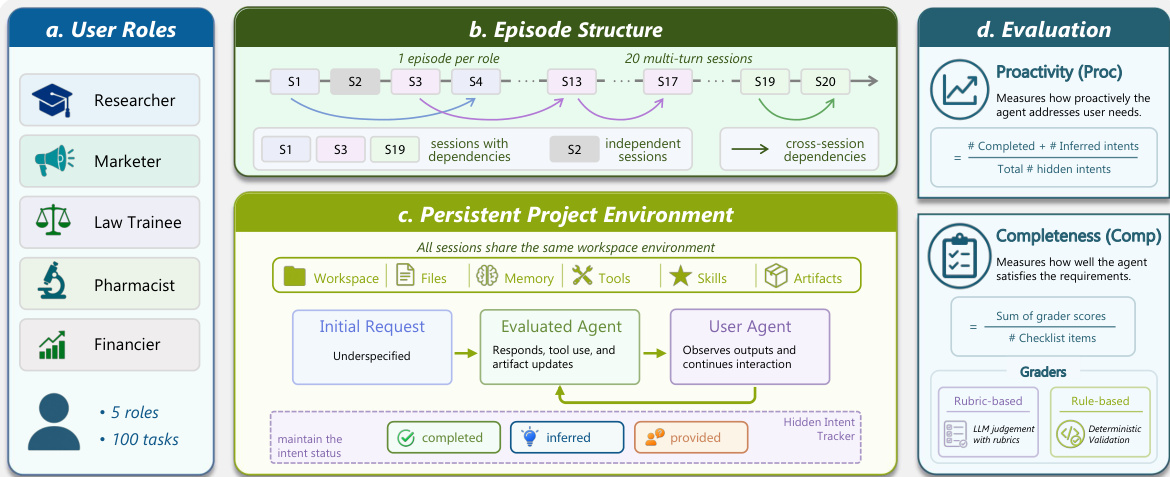
Dataset Composition and Sources: The authors introduce π-BENCH, a benchmark designed to evaluate proactive personal assistant agents across long-horizon workflows. The dataset comprises 100 multi-turn tasks distributed across five domain-specific user personas: researcher, marketer, law trainee, pharmacist, and financier. Tasks are derived from authentic professional and everyday knowledge work routines collected from domain experts and public task patterns, then sanitized to remove sensitive information while preserving realistic workflow structures.
-
Subset Structure and Key Details: Each of the five user roles corresponds to a single episode containing 20 sessions, with each session representing one multi-turn task. Within each episode, tasks are organized into six strong dependency groups where two to three tasks share essential carry-over information, alongside five largely independent tasks that test standalone workflows. The benchmark integrates 187 unique tools and 21 skills, with tasks categorized into 18 fine-grained action and reasoning types. Filtering rules prioritize artifact-centric workflows that naturally require interaction and contain realistic underspecification.
-
Data Usage and Evaluation Setup: The authors use the dataset exclusively for evaluation rather than training. Agents interact with a simulated user agent in a turn-based loop where the user tracks hidden intents and assigns them terminal statuses. The paper measures two distinct capabilities: proactivity, which assesses whether the agent infers or elicits unstated requirements, and completeness, which verifies final deliverables against a predefined checklist. No training splits or mixture ratios are applied, as the benchmark serves as a static evaluation suite.
-
Metadata Construction and Processing Pipeline: Each task is packaged as a structured configuration containing the initial request, hidden intents, checklist criteria, and metadata such as difficulty ratings. The authors deliberately craft initial requests to be natural but minimally sufficient, leaving latent requirements unstated to test proactive behavior. During construction, annotators sanitize private data, define cross-session dependencies, and validate feasibility through pilot executions and reference workflows. The evaluation pipeline retains structured tool call records, interaction histories, and file context to enable rule-based and rubric-based grading of both intent resolution and final output quality.
Method
The framework for evaluating long-horizon personal agents is structured around a multi-session interaction protocol that simulates realistic user-agent dynamics. The overall system consists of an evaluated agent operating within a persistent project environment, a user agent that simulates human interaction, and a comprehensive evaluation pipeline. The interaction unfolds in a turn-based loop where the agent responds to user inputs, performs actions such as tool use and artifact creation, and updates the workspace. The user agent observes these actions and the resulting artifacts, then generates the next user message to guide the session forward.
As shown in the figure below, the interaction begins with an initial request from the user, which may be either user-issued or environment-triggered. The evaluated agent processes the request along with the interaction history up to the current turn, denoted as Ht=(u1,a1,…,ut), and produces a response at. This response may involve internal reasoning, memory recall, tool invocation, workspace modifications, and the generation of a clarification question. The user agent then observes the agent's response and any updated artifacts, updates the tracking state for hidden intents, and generates the next user message ut+1. This process continues until all hidden intents have been assigned a terminal status.
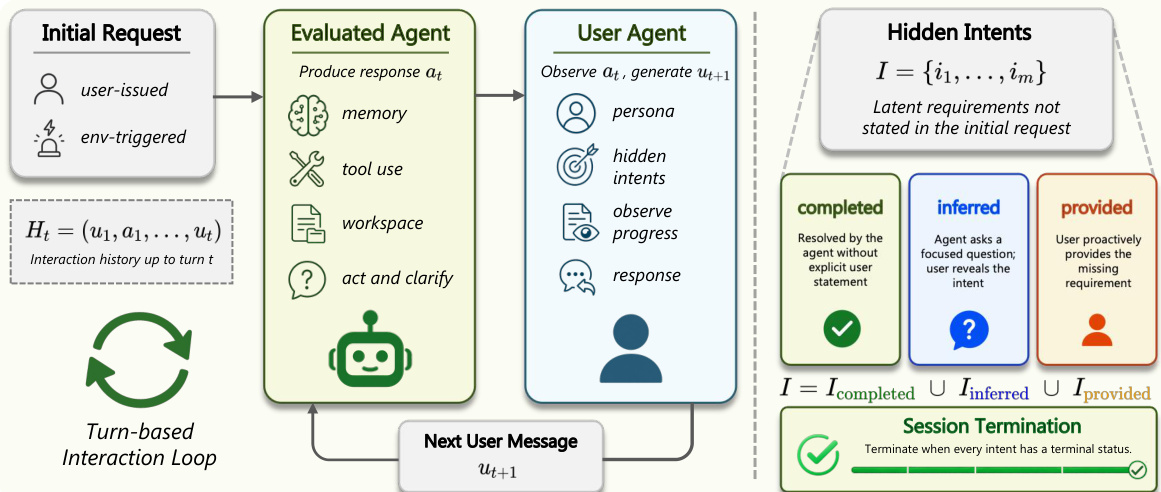
The user agent operates in a two-stage process to determine the status of hidden intents, which are latent requirements not explicitly stated in the initial request. The first stage checks whether the agent's response has already satisfied any unresolved intents through its actions, tool use, or artifact creation. If an intent is resolved without explicit user input, it is assigned the "completed" status. This stage has priority, as it captures the strongest form of proactivity. The second stage evaluates whether the agent has asked a targeted clarification question that directly addresses one or more unresolved intents. If such a question is found, those intents are assigned the "inferred" status, and the user agent provides the missing information in the next message. If no targeted question is present, the user agent selects an unresolved intent and reveals the corresponding information, assigning it the "provided" status. This two-stage protocol establishes a clear priority order: completed > inferred > provided, which directly maps to the proactivity metric.
The evaluation of the agent's performance is conducted along two dimensions: proactivity and completeness. Proactivity, denoted as PROC, measures how actively the agent identifies and addresses hidden requirements. It is computed as the ratio of completed and inferred intents to the total number of hidden intents. Completeness, denoted as COMP, evaluates whether the final artifacts and decisions satisfy the task's verifiable requirements. This is assessed using a combination of rubric-based and rule-based graders. Rubric-based evaluation involves an LLM that judges checklist criteria from a rendered trace containing the interaction history and relevant context, providing a strict YES or NO judgment. Rule-based evaluation uses task-specific scripts to verify structured tool calls and results, ensuring precise validation of objective conditions such as file existence, exact string matching, and schema validity. The final evaluation aggregates the scores from both graders to determine overall completeness. This separation of proactivity and completeness allows for a nuanced analysis of agent behavior, distinguishing between the agent's initiative in uncovering requirements and its ability to correctly execute the final task.
Experiment
This study evaluates nine frontier language models on a long-horizon benchmark featuring multi-turn tasks with hidden intents and cross-session dependencies, all executed under a unified agentic scaffold. Each experiment validates two distinct operational capabilities: proactivity, which assesses an agent's ability to uncover and resolve unstated user requirements before explicit disclosure, and completeness, which measures whether final task artifacts satisfy verifiable checklists. The results demonstrate that these metrics capture fundamentally different behaviors, as models frequently achieve high task completion through reactive user clarification while scoring lower on proactive intent discovery. Additionally, the analysis reveals that prior interaction history significantly boosts proactive capability, while performance varies across professional domains based on workflow structure and the complexity of latent requirements.
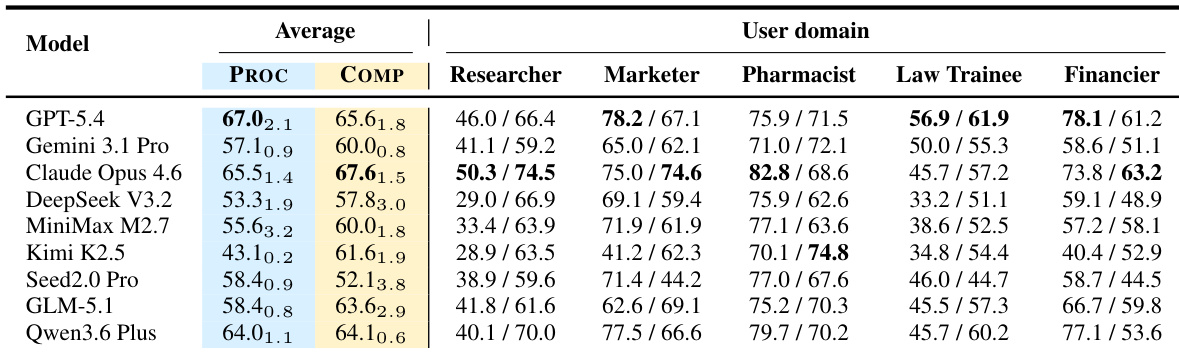
The authors evaluate agent performance on proactivity and completeness using a benchmark that assesses whether agents resolve hidden intents proactively and ultimately satisfy task requirements. Results show that different models exhibit distinct strengths, with some achieving high proactivity through early intent resolution and others excelling in final task completion despite weaker proactive behavior. The evaluation highlights the separation between these two capabilities, as agents can achieve high completeness without high proactivity and vice versa. Proactivity and completeness are distinct metrics that can diverge, with some models excelling in one while lagging in the other. Models vary in their ability to resolve hidden intents proactively, with differences in performance linked to task type and prior interaction history. The evaluation reveals that agents often rely on user-provided information for hidden intents, even when they can complete tasks after such disclosure.
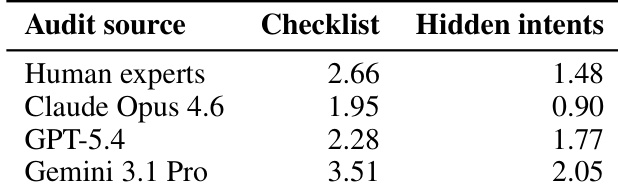
The authors evaluate agent models on proactivity and completeness, measuring how effectively they resolve hidden intents and satisfy task requirements. The results show that models vary significantly in their ability to proactively identify and address unstated needs versus completing visible tasks, with some achieving high performance in one area while lagging in the other. The evaluation highlights that prior interaction history improves proactive intent resolution, and that different task types stress distinct capabilities. The authors use a structured approach to assess both the initiation of requirements and the final outcome of workflows. Models exhibit varying levels of proactivity and completeness, with some excelling in one dimension while underperforming in the other. Prior interaction history significantly enhances a model's ability to proactively resolve hidden intents. Different task types emphasize distinct capabilities, with some requiring strong proactive discovery and others focusing on final task completion.
The authors evaluate agent performance on proactivity and completeness across multiple user domains, using a benchmark that measures whether agents resolve hidden intents proactively and satisfy task requirements. The results show that models vary in their ability to identify unstated needs versus completing tasks, with some achieving high completeness but low proactivity, and others excelling in early intent resolution but falling short in final execution. Performance differences are consistent across repeated runs, and the evaluation reveals that prior interaction history significantly improves proactive intent resolution. Models show distinct patterns in proactivity and completeness, with some excelling in one area while underperforming in the other. Prior interaction history significantly enhances proactive intent resolution, indicating the importance of context reuse. Performance varies across user domains, with some domains being easier due to structured workflows and others more challenging due to complex decision-making requirements.
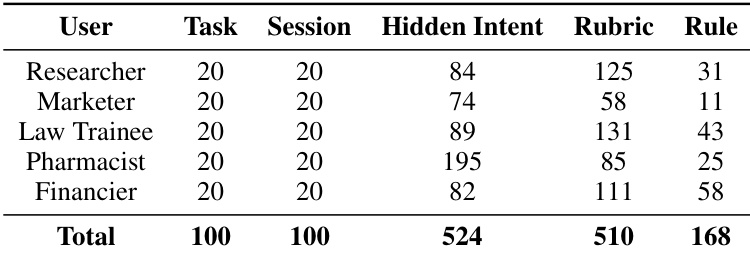
The authors evaluate multiple large language models on a benchmark that measures both proactivity and completeness in long-horizon tasks. Results show that models vary significantly in their ability to resolve hidden intents proactively versus completing task requirements, with some models excelling in one dimension while lagging in the other, indicating that these metrics capture distinct capabilities. The performance differences across domains also highlight that certain task types, such as those requiring scientific constraints or legal judgments, place different demands on agent behavior. Models exhibit a trade-off between proactivity and completeness, with some achieving high scores in one metric but not the other. Performance varies substantially across user domains, with Pharmacist tasks being the easiest and Law Trainee and Financier tasks the most challenging. Prior interaction history significantly improves proactive intent resolution, suggesting that context reuse is crucial for effective assistance.
{"summary": "The authors evaluate multiple large language models on a benchmark that measures both proactivity and completeness in long-horizon agent tasks. Results show that models differ significantly in their ability to proactively resolve hidden intents versus completing task requirements, with some models excelling in one dimension while lagging in the other, indicating that these capabilities are distinct and not always aligned.", "highlights": ["Models exhibit varying strengths in proactivity and completeness, with some achieving high scores in one metric but not the other.", "Proactive intent resolution is more challenging than task completion, as evidenced by lower proactivity scores across most models.", "The benchmark reveals that prior interaction history significantly improves proactive intent resolution, suggesting the importance of context continuity in agent performance."]
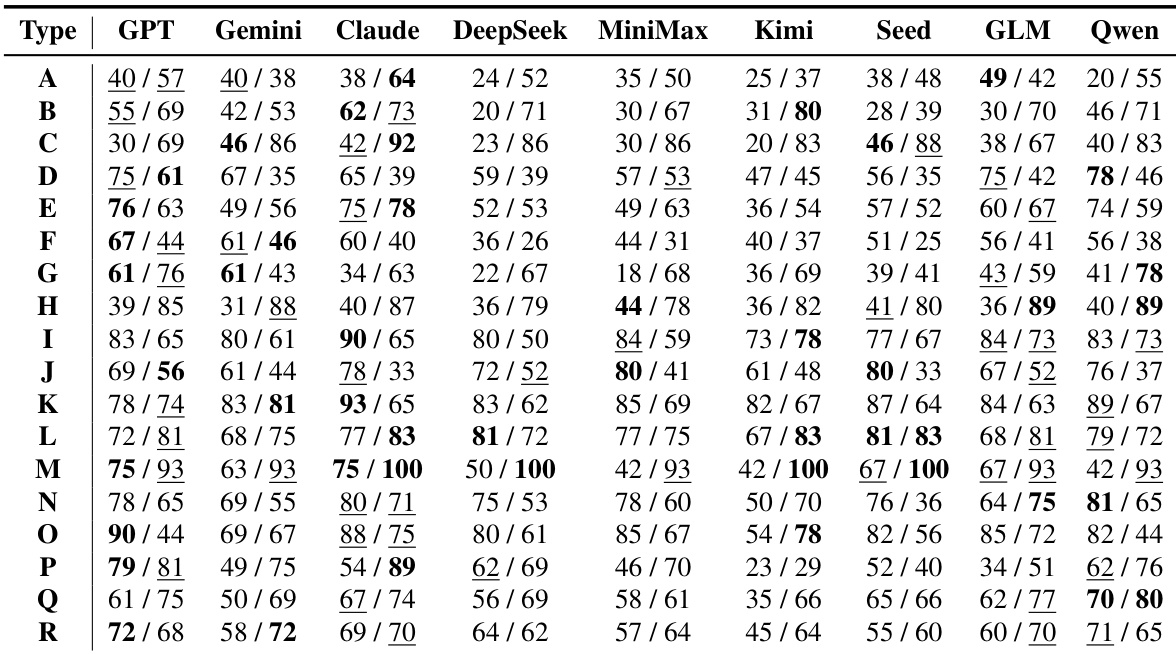
The authors evaluate multiple large language models on a benchmark designed to measure proactivity in resolving hidden user intents alongside completeness in final task execution across long-horizon workflows. The experiments validate that these two capabilities operate largely independently, as models consistently demonstrate distinct strengths in one area while lagging in the other. Analysis reveals that task complexity and domain constraints significantly shape agent performance, while maintaining prior interaction history substantially enhances proactive intent resolution. Ultimately, the findings emphasize that effective agent design requires separate optimization for early requirement discovery and reliable workflow completion.