Command Palette
Search for a command to run...
ESPnet-SDS: مجموعة أدوات وعرض موحد لأنظمة الحوار المنطوق
ESPnet-SDS: مجموعة أدوات وعرض موحد لأنظمة الحوار المنطوق
شغّل تجربة Mistral-7B-v0.3 عبر الإنترنت
الملخص
العنوان: (غير متوفر)
الملخص: أدت التطورات في نماذج الصوت الأساسية (FMs) إلى إثارة الاهتمام بأنظمة الحوار المنطوق من البداية إلى النهاية (E2E)، لكن تعدد واجهات الويب المختلفة لكل نظام يجعل من الصعب مقارنتها والتباين بينها بشكل فعال. وتحفيزاً من هذا التحدي، نقدم أداة برمجية مفتوحة المصدر وسهلة الاستخدام مصممة لبناء واجهات ويب موحدة لمختلف أنظمة الحوار المنطوق المتسلسلة ومن البداية إلى النهاية. توفر عرضنا التجريبي أيضاً للمستخدمين خيار الحصول على مقاييس تقييم آلية فورية، مثل: (1) زمن الاستجابة (الزمن الكامن)، (2) القدرة على فهم مدخلات المستخدم، (3) تماسك وتنوع وملاءمة استجابة النظام، و(4) وضوح وجودة الصوت للمخرجات الناتجة عن النظام. وباستخدام مقاييس التقييم هذه، قارنا بين مختلف أنظمة الحوار المنطوق المتسلسلة ومن البداية إلى النهاية، مع استخدام مجموعة بيانات محادثات بين إنسان وإنسان كنموذج بديل. وتُظهر تحليلاتنا أن الأداة تتيح للباحثين مقارنة والتباين بين التقنيات المختلفة بسهولة، مما يوفر رؤى قيمة، مثل ملاحظة أن أنظمة E2E الحالية تتميز بجودة صوت أدنى واستجابات أقل تنوعاً. يمكن الاطلاع على مثال تجريبي تم إنتاجه باستخدام أداتنا هنا: https://huggingface.co/spaces/Siddhant/Voice_Assistant_Demo.
One-sentence Summary
The authors introduce ESPnet-SDS, an open-source toolkit that consolidates fragmented web interfaces into a unified platform equipped with automated evaluation metrics, enabling direct comparison of cascaded and end-to-end spoken dialogue systems and demonstrating that current end-to-end models exhibit poorer audio quality and less diverse responses.
Key Contributions
- The paper introduces ESPnet-SDS, an open-source toolkit that unifies web interfaces for cascaded and end-to-end spoken dialogue systems within a modular Gradio-based architecture. By integrating multiple speech recognition, language, and synthesis modules, the framework supports over forty pipeline configurations and full-duplex audio interaction.
- The toolkit incorporates a standardized evaluation pipeline that automatically computes real-time metrics for latency, input comprehension, response relevance, response diversity, and output intelligibility. This unified assessment framework enables direct technical comparison across disparate dialogue architectures without requiring custom interface configurations.
- Benchmarking against a human-human conversation dataset reveals that current end-to-end models exhibit lower audio quality and reduced response diversity compared to cascaded alternatives. These empirical findings establish concrete performance baselines for evaluating next-generation spoken dialogue architectures.
Introduction
Spoken dialogue systems power voice assistants and intelligent devices by enabling natural human-AI conversations through traditional cascaded pipelines or emerging full-duplex end-to-end audio foundation models. Establishing standardized evaluation methods for these architectures is critical for advancing conversational AI and ensuring reliable real-world deployment. However, prior implementations rely on fragmented web interfaces, inconsistent backend infrastructures, and ad hoc testing protocols, which severely hinders objective comparison and reproducibility. To address these gaps, the authors introduce ESPnet-SDS, an open-source toolkit that consolidates dozens of cascaded and end-to-end dialogue models into a single Gradio-based interface. By embedding automated conversational metrics and human feedback collection directly into the workflow, the toolkit allows researchers to systematically benchmark system performance, quickly identify architectural trade-offs, and accelerate the development of more robust spoken dialogue technologies.
Dataset
- The authors primarily use the public Switchboard human-human conversation corpus as their benchmark, supplemented by a small-scale pilot study involving only consenting research collaborators.
- The Switchboard subset provides standard conversational data for evaluation, while the pilot subset contains voluntarily recorded interactions governed by informed consent and a visible privacy notice.
- This data is used to assess both cascaded and end-to-end spoken dialogue systems. The authors compute evaluation metrics on the fly without persistently storing user inputs, and all system modules are released as open source.
- Data collection via the web interface is disabled by default to prioritize privacy. The pipeline does not apply explicit cropping or custom metadata construction, relying instead on the native structure of the benchmark corpus and opt-in pilot recordings for transparent assessment.
Method
The authors design ESPnet-SDS as a modular framework to support both cascaded and end-to-end (E2E) spoken dialogue systems, enabling flexible integration and evaluation of various components. The toolkit's architecture is built around wrapper classes for individual modules—VAD, ASR, LLM, and TTS—implemented under the espnet2/sds directory, as shown in the framework diagram. These wrappers encapsulate existing open-source models and their inference codebases, allowing seamless integration via publicly available checkpoints. The core of the system is the ESPnet_SDS_Model_Interface class, which provides a unified interface for orchestrating these modules in both cascaded and E2E configurations. This interface enables real-time interaction, including turn-taking managed by a VAD module, and supports dynamic switching between different system variants.
The system supports a plug-and-play architecture that allows users to select from a variety of cascaded and E2E dialogue systems, with a total of 41 system variations supported through the web interface. Models are loaded on-the-fly to avoid memory constraints, enabling seamless switching between configurations, though loading a new model temporarily hides output boxes and may introduce a brief delay. The web interface, built using Gradio, streams user audio input (A), processes it through the selected dialogue system, and renders the output, which includes synthesized speech and text responses (B). This interface also displays on-the-fly evaluation metrics for each component, such as ASR WER, LLM latency, and TTS quality, allowing users to assess system performance in real time (D). Additionally, the framework includes functionality to collect human feedback on the relevance and naturalness of system responses (E), facilitating human-in-the-loop evaluation.
The toolkit includes a template module (TEMPLATE/sds1) that demonstrates how to construct a complete spoken dialogue system demo using the provided interface wrapper and evaluation tools. This module contains a Run.sh script that enables users to create customized recipes for comparing different model combinations, including various ASR, LLM, and TTS components. The evaluation metrics, implemented in the pyscripts/utils/dialog_eval directory, are designed to assess performance at both sub-task and overall conversation levels. The framework further supports optional integration with a remote HuggingFace dataset to store interaction data and human judgments, though this feature is disabled by default to comply with privacy requirements.
Experiment
The evaluation utilizes the Switchboard dataset to systematically assess modular cascaded dialogue systems and an end-to-end model through automated benchmarks and human-in-the-loop trials. Experiments validate the transcription accuracy of speech recognition components, the coherence and contextual alignment of language models, and the intelligibility and quality of speech synthesis, while ablation studies confirm the pipeline's robustness to recognition errors and highlight how grammatically refined text improves audio output. Qualitative analysis indicates that although dedicated modules perform strongly, the end-to-end architecture generates more formulaic responses and exhibits reduced audio fidelity. Additionally, human interaction tests demonstrate that while the system generally produces natural and contextually relevant outputs, it struggles with conversational dynamics such as higher latency, slower pacing, and a lack of natural turn-taking behaviors.
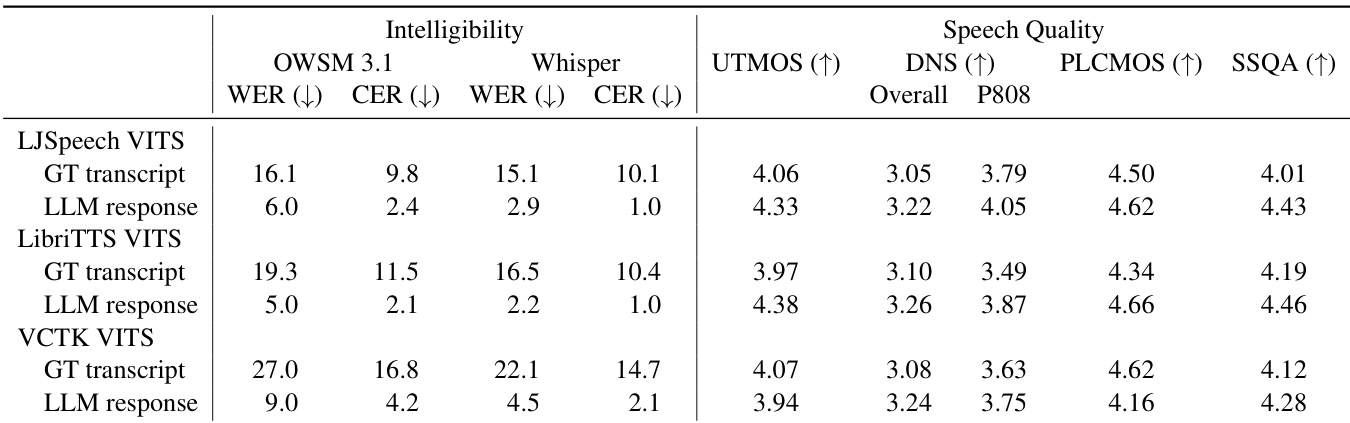
The authors evaluate various text-to-speech models using a range of metrics, focusing on intelligibility and speech quality. The the the table shows that the LJSpeech VITS model achieves the highest intelligibility and speech quality scores, while the Mini-Omni system, which generates responses end-to-end, performs worse in both categories compared to the other TTS models. The results indicate that the Mini-Omni system's synthesized speech is less intelligible and has lower audio quality. LJSpeech VITS achieves the highest intelligibility and speech quality scores among the evaluated TTS models. Mini-Omni's synthesized speech is less intelligible and has lower audio quality compared to other TTS models. The evaluation highlights a performance gap between traditional TTS models and the end-to-end dialogue system Mini-Omni in terms of speech quality.
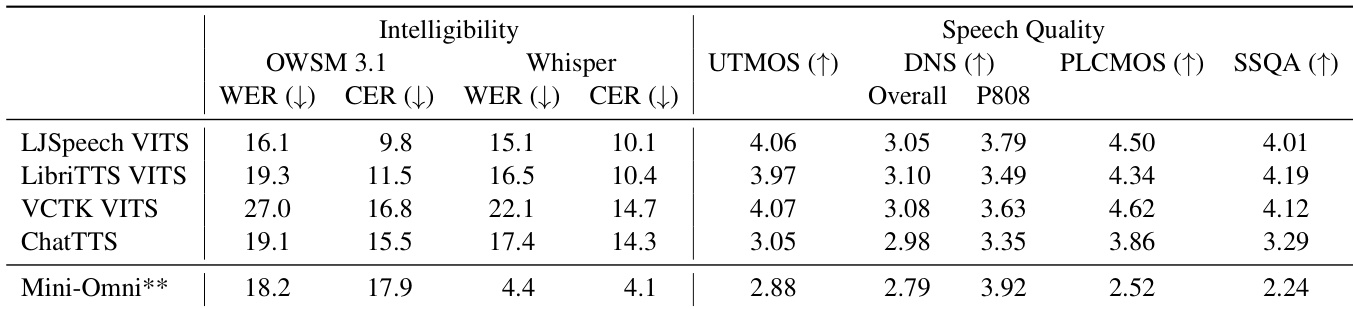
The authors evaluate various TTS models and an E2E spoken dialogue system using intelligibility and speech quality metrics, comparing performance based on ground truth transcripts versus LLM-generated responses. Results show that LLM-generated responses improve intelligibility across TTS models and that the E2E system's synthesized speech is less natural in quality compared to dedicated TTS models. The evaluation highlights differences in performance between single-speaker and multi-speaker models, as well as between systems using ground truth versus generated inputs. LLM-generated responses improve intelligibility for TTS models compared to ground truth transcripts. Dedicated TTS models produce higher speech quality than the E2E spoken dialogue system. Single-speaker TTS models achieve better intelligibility and audio quality than multi-speaker alternatives.
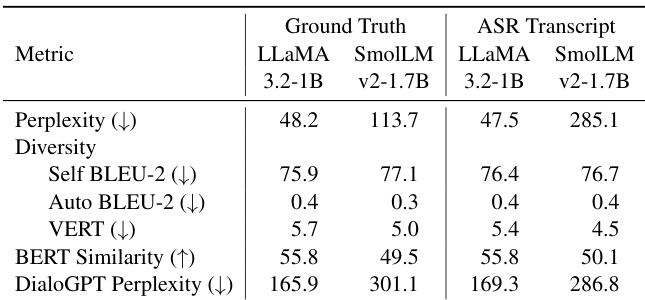
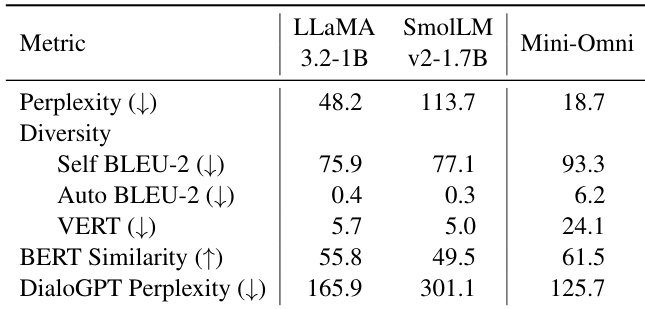
The authors evaluate various language models in a cascaded dialogue system using metrics such as perplexity, diversity, and contextual relevance. Results show that SmolLM v2 generates more diverse responses compared to LLaMA 3.2-1B, while LLaMA produces more coherent and contextually relevant outputs. The evaluation highlights differences in performance based on the input context, with LLM-generated responses improving intelligibility in TTS systems. SmolLM v2 produces more diverse responses compared to LLaMA 3.2-1B LLaMA 3.2-1B generates more coherent and contextually relevant responses than SmolLM v2 LLM-generated responses improve intelligibility in TTS systems compared to raw spoken input
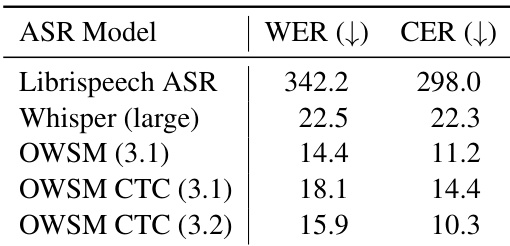
The authors evaluate various ASR models using WER and CER metrics on the Switchboard dataset, comparing their performance in terms of error rates. Results show that the OWSM 3.1 model achieves the lowest error rates, followed closely by the OWSM CTC 3.2 model, while the Librispeech ASR model exhibits significantly higher error rates. OWSM 3.1 achieves the best performance among the ASR models evaluated. OWSM CTC 3.2 performs closely to OWSM 3.1 with slightly higher error rates. Librispeech ASR shows substantially higher error rates compared to the OWSM models.
The authors evaluate different language models and an end-to-end dialogue system using text dialogue module-specific metrics, including perplexity, diversity, and context modeling. Results show that the end-to-end system produces highly coherent and contextually relevant responses but exhibits significant response overlap, leading to template-like outputs. Among the language models, one model generates less diverse responses compared to another, while the end-to-end system demonstrates higher coherence and relevance than both models. The end-to-end system produces highly coherent and contextually relevant responses compared to the language models. One language model generates less diverse responses than the other, while the end-to-end system shows high response overlap. The end-to-end system achieves higher coherence and relevance than the language models but produces template-like outputs.
The experiments evaluate dedicated text-to-speech and speech recognition models alongside large language models and an end-to-end spoken dialogue system to validate their respective capabilities in acoustic generation and conversational reasoning. Qualitative analysis reveals that specialized modular components consistently outperform the unified end-to-end framework in both speech quality and recognition accuracy. While the integrated dialogue system produces highly relevant and contextually aware responses, it suffers from repetitive outputs, whereas standalone language models present a distinct trade-off between response diversity and contextual coherence. Ultimately, the findings highlight a clear performance gap between purpose-built architectures and integrated systems, while confirming that synthetic text inputs can meaningfully enhance downstream speech intelligibility.