Command Palette
Search for a command to run...
نشر تعليمي لتقليل الأبعاد بنقرة واحدة
الملخص
Please provide the title and abstract you would like me to translate.
One-sentence Summary
This tutorial and survey unifies spectral dimensionality reduction as kernel principal component analysis with distinct kernels, outlines semidefinite programming-based kernel learning for transduction, and details Maximum Variance Unfolding alongside its supervised variants, out-of-sample extensions using eigenfunctions and kernel mapping, and landmark adaptations for big data.
Key Contributions
- Spectral dimensionality reduction methods are unified as kernel Principal Component Analysis with distinct kernels, interpretable through eigenfunction learning and distance-matrix representations.
- The tutorial establishes the necessary Semidefinite Programming background and details kernel learning via SDP for transductive tasks alongside the Maximum Variance Unfolding and Semidefinite Embedding frameworks.
- Supervised MVU variants utilizing nearest neighbor graphs, class-wise unfolding, Fisher criteria, and colored formulations are detailed alongside out-of-sample extensions via eigenfunctions and kernel mapping, while additional adaptations including action respecting embedding, relaxed MVU, and landmark MVU for big data are introduced.
Introduction
Spectral dimensionality reduction techniques are essential for extracting low-dimensional geometric structures from complex, high-dimensional datasets, yet they have historically evolved as isolated algorithms with fixed kernel formulations. This fragmentation limited adaptability and made it difficult to automatically identify the optimal kernel for unfolding data manifolds. The authors leverage this unified theoretical perspective by demonstrating that all spectral methods can be reformulated as kernel Principal Component Analysis with dataset-specific kernels. Building on this insight, they introduce a comprehensive framework that applies semidefinite programming to learn optimal kernels, enabling Maximum Variance Unfolding to stretch manifolds along their intrinsic dimensions. The paper systematically surveys this unified approach, detailing supervised extensions, out-of-sample generalization techniques, and scalable variants, ultimately providing practitioners with a clear roadmap for adapting manifold learning to diverse real-world applications.
Dataset
• Dataset composition and sources: The authors do not describe any dataset composition or sources in the provided text. The excerpt only includes author affiliations and publication metadata. • Key details for each subset: No subset breakdowns, sizes, sources, or filtering criteria are mentioned. • How the paper uses the data: The authors do not specify training splits, mixture ratios, or data processing workflows. • Cropping strategy, metadata construction, or other processing details: No cropping methods, metadata generation steps, or additional processing techniques are outlined.
Method
The core methodology of the approach revolves around learning an optimal kernel matrix that enables maximum variance unfolding of data manifolds, a process formalized through semidefinite programming (SDP). This framework, known as Maximum Variance Unfolding (MVU) or Semidefinite Embedding (SDE), unifies various spectral dimensionality reduction techniques by treating them as instances of kernel Principal Component Analysis (PCA) with different kernel definitions. The primary goal is to find a kernel that maximizes the variance of the data's embedding while preserving its local geometric structure.
The framework begins with a dataset X:={xi∈Rd}i=1n, aiming to find a low-dimensional embedding Y:={yi∈Rp}i=1n. Unlike standard PCA, which operates directly in the input space, MVU performs this embedding in the Reproducing Kernel Hilbert Space (RKHS) defined by a kernel function k(⋅,⋅). The embedding is defined as yi=ϕ(xi), where ϕ(⋅) is a mapping function. The key insight is that the embedding is fully determined by the kernel matrix K∈Rn×n, where Kij=ϕ(xi)⊤ϕ(xj), which is a symmetric and positive semidefinite (PSD) matrix.
The optimization problem is designed to find the best such kernel matrix. This is achieved by maximizing the variance of the embedding, which is equivalent to maximizing the trace of the kernel matrix, tr(K). However, this maximization is subject to critical constraints that define the manifold's structure. The first constraint enforces local isometry, ensuring that the relative distances and angles between neighboring points in the input space are preserved in the embedding space. This is formalized as τij(Kii+Kjj−2Kij)=τij(Gii+Gjj−2Gij), where Gij=∥xi−xj∥22 is the squared Euclidean distance in the input space, and τij is an indicator function that is one if xj is a neighbor of xi (typically determined by a k-Nearest Neighbors graph) and zero otherwise.
A second constraint ensures that the embedding has zero mean, removing the translational degree of freedom. This is achieved by double-centering the kernel matrix, which is equivalent to the constraint ∑i=1n∑j=1nKij=0. The final and most crucial constraint is that the kernel matrix must be positive semidefinite, K⪰0, which is a fundamental requirement for a valid Mercer kernel. The complete SDP optimization problem is thus to maximize tr(K) subject to these three constraints. 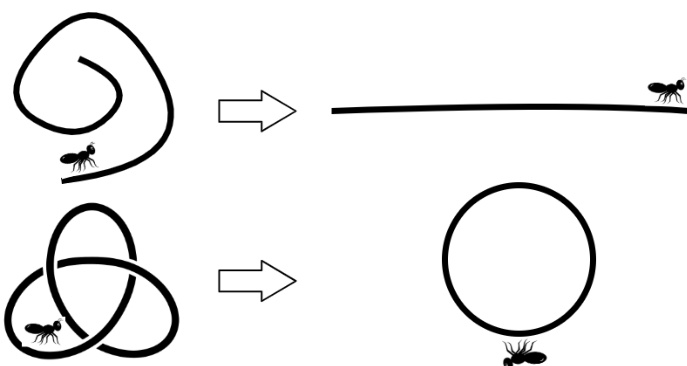
Once the optimal kernel matrix K is learned via SDP, the final embedding is computed from its eigenvectors and eigenvalues. The embedding of a point x is obtained by projecting it onto the eigenvectors of K. The k-th dimension of the embedding yk(x) is calculated as yk(x)=δkvki, where vk is the k-th eigenvector and δk is the corresponding eigenvalue of K. The number of dimensions p in the final embedding is determined by selecting the top p eigenvectors corresponding to the largest eigenvalues, often identified by a scree plot to find a significant gap between successive eigenvalues.